
Privacy Implications for the First Wave of Ed Tech in a COVID-19 World
By Daniel Lee | March 30, 2020
Educational institutions have been among the first to implement sweeping operational changes to adjust to and combat the realities of COVID-19. As of this writing, over 100 colleges and universities have shifted their courses from physical to online classrooms to mitigate the dangers and spread of coronavirus, with a growing number of primary and secondary (K-12) school districts also rapidly adopting various distance learning models. Instead of calling on raised hands, passing out homework sheets, or filling lecture halls, instructors are now fielding homework questions via Twitter, disseminating study guides via YouTube, and leveraging online collaboration platforms such as Zoom or Google Hangouts to host synchronous lectures. This has spawned a mad rush to understand how to live and learn in this new world: instructors scrambling to digitize curriculum and content, CIO offices frantically approving new learning technologies and tools, and students and teachers alike adjusting to a wholly new learning environment.

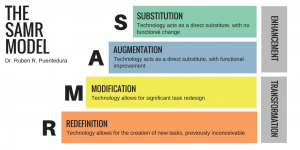
While these changes have been largely disruptive operationally, they are remarkably less disruptive in the transformative sense compared with how we might traditionally evaluate education technology initiatives. Instead, “first wave” education technology responses to COVID-19, such as virtualizing the delivery of learning content and resources, largely focus on the substitution of physical tools or processes with virtual ones, with little to no functional change from the status quo. Dr. Ruben Puentedura’s SAMR model provides a helpful framework for thinking about the varying degrees of technology integration in teaching. Using the SAMR model, we broadly categorize most first wave initiatives as “substitution” given the primary objective of integrating technology to enable students to participate in class without being physically co-located with teachers, and not necessarily to redefine education practices or promote a higher standard for learning efficacy overall. If we can convincingly conclude that many first wave initiatives are largely focused on the substitution of existing classroom functions with digital ones, this also provides a really focused point of comparison for analyzing the legal, ethical, and privacy implications of these first wave education technologies against their analog counterparts.
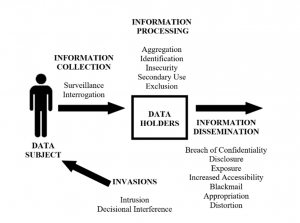
Frameworks like Nissembaum’s contextual integrity are particularly helpful here to compare and contrast the information flows and inherent privacy implications for physical tools with those of their virtual counterparts, especially for simple scenarios such as taking attendance, participating in lecture, or submitting an assignment where the only difference between physical and virtual is the tooling itself. Traditional classroom information flows between the data subject (the student) and the recipient (the instructor) are generally subject to the transmission principle that this information is secured and employed only within the boundaries and needs of the classroom or school itself. However, when virtual tools are employed for these activities, third-party entities emerge as additional recipients of this information and compromise the contextual integrity of physical classroom activities. We reach similar conclusions when considering Solove’s taxonomy. In most scenarios, data subjects remain mostly consistent across both the physical and virtual toolsets, but the presence of third-party entities in virtual alternatives extends who participates in information collection, data holding, information processing, and information dissemination of personal student and instructor information in these scenarios.
The reason for these deviations, of course, is that many first wave tools are oriented towards making analog information digital and easily accessible by many, and the digitization of these educational tools and processes, by definition, requires the hosting and distribution of classroom content to third-parties. As a result, when classroom information is shared broadly through online platforms like Twitter, Youtube, or Zoom, that information is exposed to a much broader ecosystem of service providers who are traditionally not in play at all or who participate to varying, but lesser degrees in physical classroom environments. As the virtualization of analog information also brings the possibility of generating additional information on data subjects based on their attendance and participation in specific classroom events and their social relationships to other participants, we must also consider the various ways that this data can be fused with or exploited to generate additional insights about data subjects that might have been previously accessible.
As a result, we must carefully consider how the original transmission principles and contexts are either enabled or jeopardized by the involvement of third-party entities, and identify new processes or methods for protecting personal information in virtual classroom settings. While first wave initiatives have made it possible to continue learning activities virtually in the face of COVID-19, they add additional complexity to the classroom privacy landscape and expose new opportunities for inappropriate disclosures or misuse of personal information. We must dutifully consider the ethical, legal, and privacy implications of these first wave technologies and the accountability for safeguarding personal data, especially as many third-party technologies abide by their own set of governing policies on how that information is used, disseminated, and secured.
References:
1: https://www.npr.org/2020/03/13/814974088/the-coronavirus-outbreak-and-the-challenges-of-online-only-classes
2:http://www.hippasus.com/rrpweblog/archives/2014/06/29/LearningTechnologySAMRModel.pdf
3: https://s.abcnews.com/images/International/coronavirus-school-japan-ap-rc-200305_hpMain_16x9_992.jpg













{kind=link}