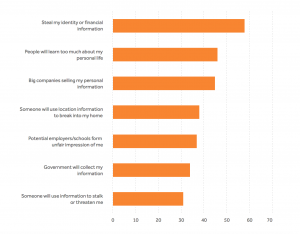
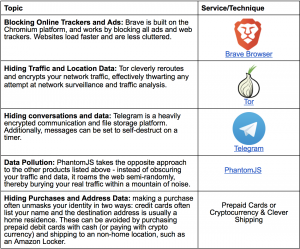
Are regulations like GDPR right solution to address online privacy concerns?
By Anonymous | July 19, 2019
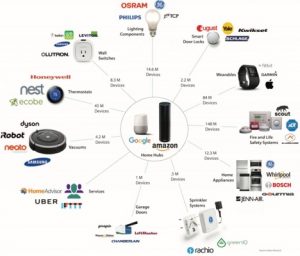
With the internet turning the entire world into a potentially addressable market, anyone can build a niche business as long as they can find their customers. Personalized ads solve this problem by enabling businesses of all sizes to reach their customers from anywhere in the world. Ad-supported services such as Facebook and Google are extremely popular with the users because of their business model- they provide excellent service at free of cost. Google search , for example, enable anyone to find answers to anything. This immense value proposition of data driven free services loved by users and valued by businesses have revolutionized the economy. But for this business model to work , users need to share their data so that the internet companies can continuously improve their products and serve personalized ads.
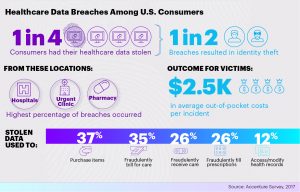
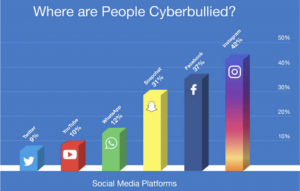
However, Individual users have little knowledge or control of their personal data that these internet companies are using and sharing . A resulting conflict has emerged between the necessity of data collection and sharing for companies on the one hand and consumer autonomy and privacy for individuals on the other.
What is GDPR?
The first major regulatory framework to address this dilemma is arguably GDPR or “The General Data Protection Regulation” which came into effect starting May 25th , 2018. GDPR is a regulation in European Union (EU) on data protection and privacy for all citizens of the EU. Due to the open nature of the web, GDPR rules apply to any business that markets or sells their products to EU consumers or whenever a business collects or tracks the personal data of an individual who is physically located in the EU.
GDPR is designed to make it easier for consumers to protect their privacy and enable them to demand greater transparency and accountability from those who use their data. It mandates that businesses that collect and use personal data must put in place appropriate technology and processes to protect personal data of their consumers and sets substantial fines for failing to comply.
GDPR also introduced the concept of “privacy by design”which requires business to design their application in such a way that it collects only the least amount of personal data necessary for their purpose and receives person’s express and specific consent before collecting that limited personal data.
Impact of GDPR
Consumer attitude on Privacy
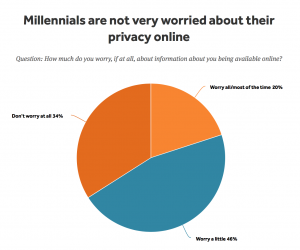
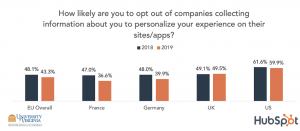
Hubspot partnered with the University of Virginia to explore how consumer attitudes have changed post GDPR. A group of more than 1000 subjects were surveyed across the EU and the US and the results show that consumer sentiment on privacy has actually decreased in 1 year since GDPR went into effect.
Fewer consumers are concerned with how companies are collecting their personal data.
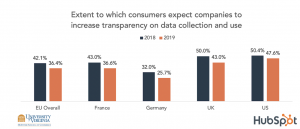
Fewer expect organizations to be more transparent with their policies on data collection, use and sharing with third parties.
Competition
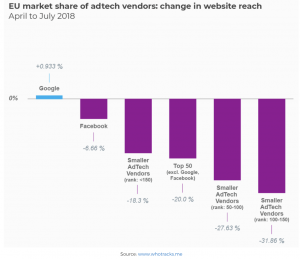
An analysis of the impact of GDPR on the ad-tech industry suggests that regulation can reinforce dominant players at the expense of smaller entities by further concentrating power — because big companies have greater resources to tackle compliance.
Is there a better way to address privacy concerns?
Though it is still early days, studies suggest that GDPR is likely not working the way it was expected to. Consumers have either become more indifferent towards their online privacy concerns or their confidence on the protection mechanisms have declined in the first year since GDPR went into effect. There is also growing evidence that GDPR is likely ending up in harming competition and helping internet giants to further increase their market share at the expense of the smaller players.
Instead of a one size fits all regulatory approach like GDPR , it might be worthwhile to define the context specific substantive norms for privacy as suggested by Nissenbaum and use that to constrain what information websites can collect, with whom they can share it, and under what conditions it can be shared. Secondly , conditions could be created for users to see not simply what they have shared — which GDPR requires, but also their profile information that gets built after merging their inputs with other data sources. Today, many users don’t care about privacy, particularly if the service is useful or saves them money. At the same time , most users likely have no idea what information about them that these internet companies may have uncovered. They might change their minds if they actually saw their profile data, not simply the raw inputs. And finally, once empowered , users should be trusted to take care of their own privacy.
References
[1] Nissenbaum-contextual-approach-privacy-online
[2] General-data-protection-regulation-consumer-attitudes
[3] Gdpr-effect-on-competition