AI innovation or exploitation : Uber’s rideshare digital economy
(Musings of a private citizen)
By Anonymous | December 6, 2019
Taxicabs have been around for decades, regulated and controlled by city governments and other local transportation authorities across the civilized world in one of the following ways – drivers have to apply for a taxicab license or permit with a city or state agency, they need to have a good driving record and often are governed by local rules around fares, rights they must afford to their customers and when and how much they can charge for their cab service during the day, night, busy traffic, airports, etc…

Behind the innovative ideas like Uber or Lyft is a very principled thought of sharing – a very basic human trait that each of us learns as early as we are probably learning to walk. Share your food, your toys, your books, pencil and then as adults, share your space, sometimes possessions for the greater good – benefits like reducing waste and traffic when we think of things like carpools and friends driving friends together.
There are limits to human sharing — sharing does not scale up, after all we know that all friendships, all neighbors, colleagues are not created equal. We all don’t have the same possessions, and hence our ability or willingness to share can be varied and hence reciprocity may be uneven, resulting in broken hearts, spoilt relationships and a system of carpooling that does not scale. Thus enter – ridesharing services like Uber.
Due to income disparity, a section of the community that is left behind finds a way to make an income as a driver supplementing during times of hardship or when one might be in job training or when in between jobs or just not suitably qualified or experienced for available local jobs.
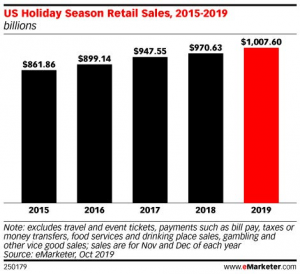
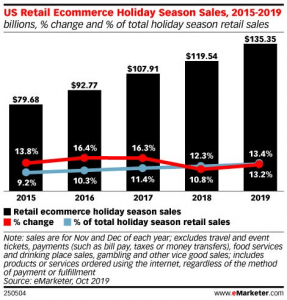
Innovation creates hundreds of thousands of “gig economy” jobs and results in new income rivers to flow from the pockets of haves to have-nots. This in turn increases access to resources like education, child care, college education and fill the gaps left despite public transportation in cities like Chicago, New York, New Delhi, San Francisco, Mumbai, Calcutta, London where numerous layers of local public transportation services have been in existence for decades alongside taxicab drivers.
There are some visible evils of this sharing economy, innovative yet exploitative by design. While taxicabs are regulated and have some rights, On Uber the drivers and riders are all “users” and these drivers cannot expect to be treated with employee benefits, something that is a sticking issue for those who drive 40 or more hours a week. The appeal of a gig job is far greater and fares are hard to compete with for the regulated taxicab drivers. Another major problem is that of discrimination of marginalized sections of society both as riders and drivers – the inherent biases result in drivers geting lower fares with lower ratings and customers get lower ratings and have to often wait longer time periods in order to get their rides.

The algorithm cannot repair the biases of society – Uber amplifies these biases. Finally, Uber users have to put up with a direct invasion of privacy. The app continues to track the rider after they are not with Uber anymore resulting in collection, processing and utilization of private data that should not have been collected.
It has been known for some time now that Uber has poor internal privacy safeguards and the data they collect can be used in the name of “R&D” projects within Uber where data scientists have been found to be using user data while the User privacy policy remains devoid of a proper disclaimer of these research objectives and how these may affect the user community.

While Uber is a technology platform, it does have a powerful ability to manipulate the market. Using AI to reinforce learning ways to test the tolerance of a rider when it comes to price point and the tolerance of a driver to accept a lower price, the margin between the driver and the rider is Uber’s profit.
Uber is effectively charging variable “user fee” based on the value of the transaction, the ability of the customers to let go of their bottomline in the interest of convenience and a shared mindset.Uber is doing this while capturing a lot more data than is needed in broad daylight (and at night) from all its customers blurring the line between innovation and exploitation.