Genetic profiling – Gaming the “lottery of life”
By Anonymous | November 20, 2019

Background: Genetics for healthier children
Large-scale genome-wide association studies have deepened our understanding of the interplay between genetic and environmental factors and individual traits. A 2015 meta-analysis of heritability studies showed that 40% of individual differences in personality were due to genetic, while 60% are due to environmental influences [1].
Individually, genetic differences have little consequence. But combined effects can be big. Single nucleotide polymorphism (SNP) profiling looks for combinations of differences for which research has shown correlations with diseases, such as cancer, diabetes and heart disease. Common procedures test for almost 1m SNPs. SNP profiling is already used to enhance desired attributes in livestock, so we can assume it will also work on people.
SNP profiling can be applied together with in-vitro fertilisation (IVF) to select which of a group of viable embryos should be implanted and brought to term. SNP-profiling companies such as Genomic Prediction are already offering analysis services to prospective parents.
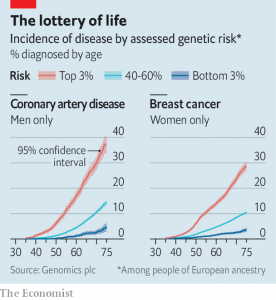
Optimising genetic profiles promises healthier children. SNP can be used to draw up lifetime risk profiles for various medical conditions, such as coronary artery disease or breast cancer [2]. The image below shows that a British woman’s average 10-year risk of developing breast cancer at the age of 47 is 2.6%. Women who are in the top 3% risk group reach this level already at the age of 40, while the bottom 3% do not cross this threshold until they were 80.
SNP can also enable the early identification of single-gene disorders which might have severe consequences when passed on from parents to children. Furthermore, SNP profiling does not involve the dangers of gene editing, i.e. experimenting with new genetic variants.
Concerns and ethical considerations
SNP-profiling raises numerous ethical questions. The technology may provide a way to influence other factors that are not directly linked to health, e.g. height and intelligence. SNP profiling has been found to be predictive of abstract characteristics such as higher-level cognitive functions (e.g. problem-solving), television-viewing habits or the likelihood of being bullied at school [2].
SNP profiling for non-medical attributes is not yet offered by SNP profiling companies, but it is likely – as science progresses – that it will be offered as there are no legal obstacles restricting such services.
Private laboratories offering SNP have developed intellectual property on tests and procedures, so they might consider information to be proprietary. It is unclear whether prospective users of the service are sufficiently informed [3]. This might raise issues of prior consent and due process.
There is also the question of fairness: SNP and IVF are costly procedures, so access is currently restricted for those with the money to pay for it. It is a technique that could be applied from generation to generation, to further improve genetic profiles of a family over time. Thereby, SNP replicates the effects of “assortative mating”, where rich, successful people seek out each other as partners. But SNP-profiling accelerates and strengthens this effect, thereby aggravating the privileges that rich people enjoy [2]. In a worst-case scenario, it might create a genetic elite. It might also put undue pressure on people that want to leave the genetic selection up to “nature’s lottery”.
Last but not least, there is the concern of representativeness. The SNP information is gained from gene banks in industrialized countries, mainly from Europe. It is reasonable to assume that ethnical groups (e.g. from developing countries) are under-represented in the dataset. Conclusions on preferable genetic combinations could therefore be biased and wrong.
As a summary, genetic profiling may have positive health effects on future generations of children, but it is necessary to put limits on the ways that humans override natural selection mechanisms so that the technology can serve society as a whole. Direct-to-consumer medical testing needs more attention in the public debate, so that the above mentioned ethical concerns can be properly addressed.
Content references
[1] Vukasovic, T & Bradko, D. (2015) “Heritability of personality: A meta-analysis of behavior genetic studies”, Psychol Bull. 2015 Jul;141(4):769-85
[2] Economist (2019) “Gee whizz – The new genetics”, Nov 9th 2019
[3] Beaudet, A. (2010) “Ethical issues raised by common copy number variants and single nucleotide polymorphisms of certain and uncertain significance in general medical practice”, Genome Med. 2010; 2(7): 42
Image references
[1] https://pixabay.com/illustrations/dna-biology-medicine-gene-163466/
[2] https://www.economist.com/science-and-technology/2019/11/07/modern-genetics-will-improve-health-and-usher-in-designer-children