A Short Case for a Data Marketplace
By Linda Dong, October 23, 2020
In today’s digital, internet age, data is power. Using data, Netflix can generate recommendations, Facebook can tailor advertisements, and Visa can detect fraud. Google can predict your search phrase, Alexa can prompt you to restock household products, and Wealthfront can create your personalized retirement path, taking into account individual savings, spending, and investment goals.
Not only are data products powerful, but they also tend to be lucrative. Data products tend to be high-margin because the cost of goods sold is so low: companies generally do not pay users to collect their data. Whether companies are channeling these lucrative products into customer savings (by making other services free) or purely amassing these gains as company profits, the central question remains: should data collection be free?
– – – –
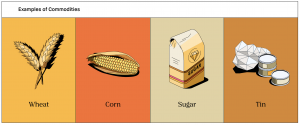
Image Source: Robinhood
Just like oil, labor, and water, data is a commodity. True – it happens to be a non-finite commodity that humans can create; however, it is also a raw material used to create sold products. Just as a bar of chocolate is made from many cacao beans, so is a web marketing analytics insight crafted from many individual browser interactions.
If you’re a chocolate maker, you’ll likely have a handful of cocoa suppliers. If you’re a web analytics company, you’ll likely have millions of users providing a little data each. However, the simple facts that your suppliers are: (i) distributed, and (ii) orders-of-magnitude more numerous do not constitute adequate justification for not compensating them.
The logistics might be simpler than you think. The idea of web-based microtransactions is not new; little known to most people, the HTTP status code of 402 [2] has been reserved for “Payment Required” use-cases for a while. While this was meant to power the opposite flow (for a requestor to present payment to access content, rather than a content provider to pay a visitor for data gathered during an interaction), this nevertheless brings us one step closer to a future where browsers might contain native wallets that can enable hundreds of microtransactions per hour.

Image Source: Mozilla Foundation
– – – –
Regulation lags behind innovation. While privacy concerns have culminated in new statutes regulating how entities should collect and use data, most protections today concern only data subjects’ rights and obligations. They have not yet evolved to address questions of compensation and profit-sharing.
Some of this is due to a lack of pressure from the general public, which, in turn, results from a lack of awareness regarding the value of data, as well as opacity regarding how companies collect and use data. Some of this is due to coercive user policies that foist consent of data collection. And some of it is due to the lack of a clear solution and path forward.
What if we reimagined the concept of privacy in an economic, rather than rights-based, context? Could browsers compete for users by providing more sophisticated privacy customizations? Could they better enable user control to select and disclose limited and specific data in exchange for monetary earnings? Could they auto-respond to pesky cookie preference pop-ups? Could they broker a new type of data marketplace between companies who want to buy data and users who want to sell data? Are these features valuable enough for them to charge users a fee, and would the public pay?
I, for one, would.
[1] https://learn.robinhood.com/articles/626haurrOd1BFJ3CkfH7xq/what-is-a-commodity/
[2] https://developer.mozilla.org/en-US/docs/Web/HTTP/Status/402