The battle between COVID contact tracing and privacy
By Anonymous | July 9, 2021
In an effort to curb COVID-19 case counts, many countries have been employing contact tracing apps as a way of tracking infections. Although implementations can differ, the main idea is that users would download an app onto their phone, which would notify them if they have possibly been exposed to COVID-19 from being in close proximity to someone who has tested positive. This sounds good in theory, until you realize the privacy implications – the developer of the app would have unhindered access to all of your movements, including where you go, who you meet, who you live with, where they go, who they meet, and so on. Classifying countries into three groups – authoritarian countries using authoritarian measures, free countries using authoritarian measures under emergency powers, and free countries using standard measures – we see that a perfect balance between contact tracing and privacy has been difficult to achieve. Let’s take a look at a few examples of each group.
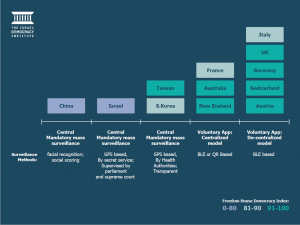
Authoritarian and authoritarian
China has taken strong measures to contain the virus, including an app that labels each individual as green (safe), yellow (potentially exposed), and red (high risk). The privacy issues are clear here, with the invasive app tracking all movements, and the algorithm of coloring individuals being a blackbox without any transparency. Although these issues remain, Chinese contact tracing has nevertheless been successful. The city of Shenzhen managed to reduce the average time of identifying and isolating potential patients from 4.6 days to 2.7 days, leading to a reproductive number of 0.4 (anything below 1 indicates that the outbreak will die).
Russia (Moscow in particular) has also taken a strong approach, forcing residents to download a QR-code based system and monitoring citizens’ movements within the city. Even with this invasive approach, Moscow has seen mass hospitalizations, second and third waves, and successive record-shattering daily death counts.
Free but temporarily authoritarian
Israel has successfully implemented a system where the Shin Bet (domestic security service) receives PII (personally identifiable information) of COVID-19 positive patients from the Health Ministry, which is then cross-referenced with a database that can identify people that came in close contact with the patient in the last two weeks. During the scheme’s first rollout, cases successfully decreased to single digits, until the whole operation was shut down by a supreme court ban. By the time the system returned under a new law three months later, Israel was well into its second wave, and case counts doubled thrice before starting to decrease again.
France initially tried to amend its emergency law to allow collection of health and location data using “any measure”. This was ultimately rejected as being too invasive, even under emergency powers. The French contact tracing app also faced major issues, sending only 14 notifications after 2 million downloads, ultimately leading a quarter of its users to uninstall the app.
Free and free
Taiwan has managed to implement a contact tracing system relying entirely on civil input and open-source software, enhancing privacy by decentralizing the data, not requiring registration, and using time-insensitive Bluetooth data. Radically different from other countries’ systems in its heavy emphasis on everything being open-source, the Taiwanese method has allowed efficient and effective contact tracing while minimizing privacy infringements.
Japan had originally used a manual form of contact-tracing, relying mainly on individually calling citizens. Once this became infeasible with large case counts and an unwillingness from respondents to fully disclose information, the government developed an app (COCOA) designed to notify users of potential exposures using Bluetooth technology, only to find out 4 months later that a bug had caused the app to fail to send notifications, drawing widespread condemnation.
Relations with privacy laws
It is important that contact tracing measures are compatible with relevant privacy laws, and that curtailments to civil liberties are kept to only what is necessary. Countries have been grappling with this issue ever since COVID-19 specific tracing apps have been available. One of the first countries to roll out a tracing app, Norway, ended up having its Data Protection Authority order the Norwegian Institute of Public Health to suspend the tracing app’s usage, as well as delete all data that was collected by it just two months after it first became available. Lithuania similarly suspended the usage of a tracing app after fears of violating EU privacy laws. Germany proposed amendments to laws that would allow broad collection of contact details and location data to fight the pandemic; both were rejected as being too invasive. Although the European General Data Protection Regulation (GDPR) creates strict limits for the collection and processing of data, it allows for some exceptions during public health emergencies, provided that the data is only used for its stated purpose – which brings us into the final important section.
Only using data for health purposes
Two principles offered by the Fair Information Practice Principles (FIPPs) provide a checklist to make sure that data collected through these systems are used appropriately – the principles of purpose specification (be transparent about how data is used) and minimization (only collect what is necessary). A privacy policy should be made public to clearly say what the tracing system can and cannot do. A lack of clear boundaries can quickly become a slippery slope of misuse, corruption, and distrust towards the government. Singapore’s contact tracing for example, originally stated that data would “only be used solely for the purpose of contact tracing of persons possibly exposed to covid-19.” Months later, the government admitted that data was used for criminal investigations, forcing both the privacy policy and the relevant legislation to be amended.
Putting everything in context
It is important to remember that contact tracing apps are simply just one part of the equation. For both countries with success and countries without success using these apps, correlation does not mean causation. We need to evaluate these systems in the greater context of the whole pandemic – although it is understandable for countries to temporarily grant emergency powers and curtail some civil liberties, we need to holistically evaluate whether the benefits of such systems outweigh the potential risks or information that we give up, and that appropriate measures are put in place to minimize potential misuses and abuses of data.
References:
https://futurism.com/contact-tracing-apps-china-coronavirus
https://www.cidrap.umn.edu/news-perspective/2020/04/study-contact-tracing-slowed-covid-19-spread-china
https://www.dailymail.co.uk/news/article-9730113/Moscow-gripped-growing-Covid-catastrophe-Russian-capital-records-144-deaths-24-hours.html
https://www.cbsnews.com/news/coronavirus-pandemic-russia-digital-tracking-system-moscow/
https://www.brookings.edu/techstream/how-israels-covid-19-mass-surveillance-operation-works/
https://www.politico.eu/article/french-contact-tracing-app-sent-just-14-notifications-after-2-million-downloads/
https://www.oecd.org/coronavirus/policy-responses/ensuring-data-privacy-as-we-battle-covid-19-36c2f31e/
https://covirus.cc/social-distancing-app-intro.html
https://asia.nikkei.com/Spotlight/Comment/Japan-s-flawed-COVID-19-tracing-app-is-digital-black-eye-for-Tokyo
https://www.bloomberg.com/news/videos/2020-07-22/contact-tracing-effective-without-invading-privacy-taiwan-digital-minister-explains-video
Contact Tracing COVID-19 Throws a Curveball to GDPR, Data Rights
https://www.technologyreview.com/2021/01/05/1015734/singapore-contact-tracing-police-data-covid/
https://www.csoonline.com/article/3606437/data-privacy-uproar-in-singapore-leads-to-limits-on-contact-tracing-usage.html
Photos:
https://www.brookings.edu/techstream/how-israels-covid-19-mass-surveillance-operation-works/
https://buzzorange.com/techorange/en/2021/05/18/gdpr-compliant-app-fights-covid-19-with-privacy-in-mind/