
Twitch and the U.S. Military – an Ethical Issue
By Harinandan Srikanth | November 27, 2020
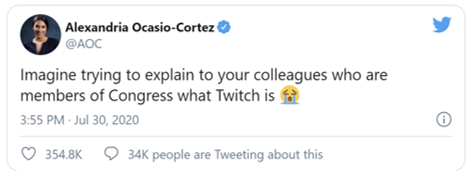
Image: How do we address the ethics or lack thereof in the military recruiting minors and young adults on Twitch when many of the representatives in Congress have never heard of Twitch?
(The Verge)
This was the frustration expressed by Congresswomen Alexandria Ocasio-Cortez from New York’s 14th district after the House of Representatives failed to vote for her bill to ban the U.S. Army from recruiting on Twitch. The draft of the amendment to the House Appropriations Bill, proposed on July 22nd, “would ban U.S. military organizations from using funds to ‘maintain a presence on Twitch.com or any video game, e-sports, or live-streaming platform.’” (Polygon.com). Twitch is a subsidiary of Amazon that specializes in video live streaming. This platform primarily supports gaming channels but also content other than gaming. Twitch has grown over the past decade to become the leading platform for online gaming, surpassing Youtube Gaming’s audience in recent years.
With 72% of men and 49% of women ages 18 to 29 engaging in gaming as a source of entertainment, the U.S. Military saw prominent live-streaming platforms like Twitch as an opportunity for recruitment from “Gen Z”. The U.S. Army launched its esports team in 2018, receiving 7,000 applicants for 16 spots, with team members streaming war-related games on “Twitch, Discord, Rivals, Mixer, and Facebook” (Military.com). The Army primarily uses fake prize giveaways on its esports channels to direct viewers to the recruitment page (Polygon.com). The number of recruiting leads has been growing rapidly, with 3,500 recruiting leads last year and 13,000 recruiting leads this year. The U.S. Navy and U.S. Air Force followed suit in recruiting gamers on live-streaming platforms (Military.com).
There was, however, an exception to the U.S. Military’s embrace of recruitment via online gaming, which was the U.S. marines. Last year, the Marine Corps Recruiting Command wrote that they would “not establish eSports teams or create branded games… due in part to the belief that the brand and issues associated with combat are too serious to be ‘gamified’ in a
responsible manner” (Military.com). Representative Ocasio-Cortez echoed this concern in another tweet:
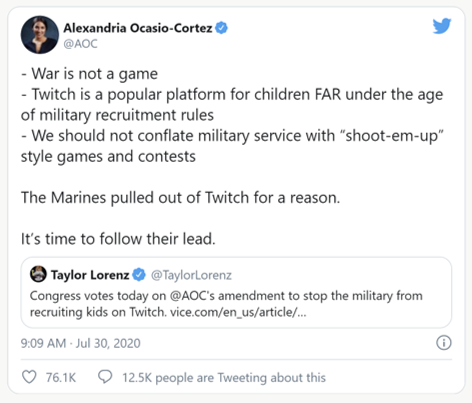
Image: AOC justifying her legislation to ban the military from recruiting on Twitch (Polygon.com).
This tweet highlights the dangerous potential for the U.S. Army’s recruitment via fake prize giveaways on esports channels to lead minors and young adults to conclude that being a member of the armed forces is as easy as playing a war-related game. Sgt. 1st Class Joshua David, deployed as a Green Beret, says that reality could not be more different from the game. According to Sgt. 1st Class Christopher Jones, “He’ll tell every single person that we engage with that there’s no comparison between the two. There’s no way soldiers are going to carry 90 pounds’ worth of equipment moving in an environment like that, essentially superhuman. You know, these environments are made up; they’re fictional” (Military.com). There is also an informed consent issue presented by this method of recruitment. If minors and young adults who are led to the U.S. Army’s recruitment page via Twitch and similar platforms get the impression that military service is just like playing games, then they are not making the choice of signing up for service in the U.S. Army with the knowledge of what being in the Army is actually like.
On the flip side, deputy chief marketing officer for Navy Recruiting Command Allen Owens says that esports also has the potential to enlighten young people about the realities of military service. If, for example, an aircraft mechanic is good at a shooter game and the person their playing with asks them if shooting is their specialty in the military, the mechanic can explain what their real job is and that being good at shooting in real life is completely different from in a game (Military.com). While those possibilities are on the horizon, however, there are steps that both the U.S. Military and live-streaming companies need to take to resolve the ethical issues presented by recruitment via platforms like Twitch.
References
1. “After impassioned speech, AOC’s ban on US military recruiting via Twitch fails House vote”. The Verge. https://www.theverge.com/2020/7/30/21348451/military-recruiting-twitch-ban-block-amendment-ocasio-cortez
2. “Amendment would ban US Army from recruiting on Twitch”. Polygon.
https://www.polygon.com/2020/7/30/21348126/twitch-military-ban-alexandria-ocasio-cortez-aoc-law-congress-amendment-army-war-crimes
3. “As Military Recruiters Embrace Esports, Marine Corps Says it Won’t Turn War into a Game”. Military.com. https://www.military.com/daily-news/2020/05/12/military-recruiters-embrace-esports-marine-corps-says-it-wont-turn-war-game.html













{kind=link}
{kind=link}
{kind=link}