The crumbs we leave… By Khakali Olenja | October 8, 2021
Background
In 1994 an engineer at Netscape by the name of Lou Montulli created the webs first cookie. Cookies are text files that reside on user’s computer and store information from the websites users visits. Montulli noticed that the internet lacked a mechanism to facilitate short-term memory storage. This meant that users who added items to their cart would not see that same item if they selected another tab or if users logged into their email account and refreshed the page the users would have to log in again. Cookies in their purest form were designed to enhance user experience, and without them we would not know the internet as we do today.
How Cookies are used today
While it is true that cookies are an integral part of the web experience, it is also true that their initial intent has been repurposed over time. Brands want to reach individuals with the highest probability of converting to customers. To target these customers, internet companies have built multibillion dollar business models using cookies to connect advertisers and customers.
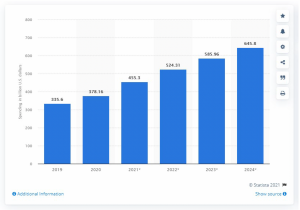
According to a report published by Statista Research Department, digital advertising spent worldwide amounted to approximately $378 billion dollars and is estimated to reach more than $645 billion dollars by 2024.
When users access a website a first-party cookie is created. First-party cookies can store attributes (e.g., Location, Cart, Time Spent, Username, Password, etc.). Brands will use these first-party cookies created to continue to share ads from their site to other websites using platforms and publishers. Platforms and publishers are companies (e.g. Youtube, Facebook, Snapchat, Google etc.) that have audiences of people who they can connect brands with via ads. In between, there are also middlemen who are dedicated to ensuring that brands ads are reaching the right people, companies like Facebook and Google serve both roles because of their scale.
As a result of the amount of money that is available to be generated from ads, platforms, publishers, and middlemen are all incentivized to collaborate with one another, which means more cookies are being generated than just the site a user is on. These additional cookies are called, third-party cookies. With third-party cookies, brands can go to Facebook or Google and request their ads be shared with users who visited the site a month ago.
The Impact on Privacy
While some individuals might think ads are nothing more than a nuisance at worst and a welcomed convenience at best, the enablement of third-party cookies allows companies to circumvent consent and allow for surveillance at scale without user’s privy to this. Some technology companies have rolled out features that will allow users to block third-party cookies which would prevent companies (e.g., Google, Apple, etc.) from identifying that a user on site A is the same user on site B. The problem is that companies like Google and Facebook are incentivized to find legal loopholes in existing policies. Facebook and Google can provide websites with a piece of code that looks like a first-party cookie data but sends all the data to a company anyway (e.g., Facebook Pixel).
Regulation has historically had trouble keeping pace with business, and the technology sector more broadly. While it is my belief that technology companies are generally well-intentioned, it is abundantly clear that the capital incentives make it materially difficult for technologies companies to self-regulate.
The Federal Trade Commission should enact legislation that provides guardrails on how customer data is being obtained and utilized beyond the terms and conditions. Open-source projects like Cookiedatabase.org – a project to bring more transparency to the world of online tracking and data collection should be referenced to help draft legislation.
Unreadable Terms and Conditions By Anonymous | October 8, 2021
Image 1. Visualization shows the time for an average user to read the terms and conditions from various platforms (LePan, 2021).
Like many others, I visit at least 10 different websites on any given day, which usually means that I agree with the “terms and conditions” and accept “cookies” on those websites without even glancing at it. Just like most of the people, I don’t have the time to read it and also naively I think companies won’t use my data in a harmful way. However, in reality, the websites I give permission to might be sharing my information to insurance companies, which can be used by insurance companies to determine my health risk and increase my monthly premiums (Vedantam, 2016).
Truth to be told is nearly all of the “terms and conditions” and privacy policies we non-voluntarily agree on are filled with tons of legal jargon, and it is extremely difficult for the general public to understand. As it is mentioned in the journal ”The Duty to Read the Unreadable”, the majority of the people do not understand the terms and conditions due to the legal language used, and this is done on purpose by the businesses (Benoliel, 2019). In addition to the language used being almost incomprehensible to understand, the length of the terms and conditions is extremely long, where the word count can even go over 10,000 words. Since the terms and conditions are excessively long and challenging to understand, according to a study, only 1 percent of the people read them (Sandle, 2020). Although the companies are legally required to put “terms and conditions” on their websites, they are not required to simplify the language used.
According to the Belmont Principles, this violates the “respect for persons” principle, as consumers have no choice but to involuntarily click the “agree” button for terms and conditions, and for cookie policies (OHRP, 2021). They are essentially agreeing to the terms without giving informed consent. You could argue that people can choose to disagree with the terms and conditions, however, in that case, they will not be granted access to the platform or service they are trying to utilize. This can be extremely harmful to peoples’ privacy and it is a form of intrusion, as companies do everything they can to make the terms and conditions lengthy and incomprehensible. So, at the end of the day, users do not have much of a choice but to involuntarily “agree” to the terms.
As people value their data privacy more each day, there are now services like “Terms of Service Didn’t Read” that summarize the important information in bullet points for the users. Although the terms and conditions should be written in simpler terms, unless there is enforcement by legal authorities, I do not see companies making their language simpler for an average user. So, services like tosdr.org will only gain more importance and become essential as far as helping the consumer to understand the main points that are mentioned in the terms. However, this is definitely not a permanent solution as it still requires a lot of effort and time from users to use services like it.
Image 2. It displays that people actually do not know what they “agree” on when they click “accept” on terms and conditions.
REFERENCES:
* Benoliel, U., Becher, S. I. (2019). The Duty to Read the Unreadable. SSRN Electronic Journal. doi.org/10.2139/ssrn.3313837.
* Cakebread, C. (2017, November 15). You’re not alone, no one reads terms of service agreements. Business Insider. www.businessinsider.com/deloitte-study-91-percent-agree-terms-of-service-without-reading-2017-11.
* Frontpage — terms of service; didn’t read. (n.d.). Retrieved October 8, 2021, from https://tosdr.org/.
* LePan, N. (2021, January 25). Visualizing the length of the fine print, for 14 popular apps. Visual Capitalist. Retrieved October 8, 2021, from https://www.visualcapitalist.com/terms-of-service-visualizing-the-length-of-internet-agreements/.
* Most online ‘terms of service’ are incomprehensible to adults, study finds. VICE. (n.d.). Retrieved October 8, 2021, from https://www.vice.com/en/article/xwbg7j/online-contract-terms-of-service-are-incomprehensible-to-adults-study-finds.
* Office for Human Research Protections (OHRP). (2021, June 16). Read the Belmont Report. HHS.gov. Retrieved October 8, 2021, from https://www.hhs.gov/ohrp/regulations-and-policy/belmont-report/read-the-belmont-report/index.html#xrespect.
* Sandle, B. D. T. (2020, January 29). Report finds only 1 percent reads ‘terms & conditions’. Digital Journal. Retrieved October 8, 2021, from https://www.digitaljournal.com/business/report-finds-only-1-percent-reads-terms-conditions/article/566127.
* Vedantam, S. (2016, August 23). Do you read terms of service contracts? not many do, research shows. NPR. Retrieved October 8, 2021, from https://www.npr.org/2016/08/23/491024846/do-you-read-terms-of-service-contracts-not-many-do-research-shows.
Risk Governance as a Path Towards Accountability in Machine Learning By Anonymous | October 8, 2021
Over the past 5 years there has been a growing conversation in the public sphere about the impact of machine learning (ML) – systems that learn from historical examples rather than being hard-coded with rules – on society and individuals. Specifically, much of the coverage has focused on issues of bias in these systems – the propensity for social media feeds, news feeds, facial recognition and recommendations systems (like those that power YouTube and TikTok) to disproportionately harm historically marginalized or protected groups. From [categorizing African Americans as “gorillas”](https://www.theverge.com/2015/7/1/8880363/google-apologizes-photos-app-tags-two-black-people-gorillas), [denying them bail at higher rates](https://www.propublica.org/article/machine-bias-risk-assessments-in-criminal-sentencing) than comparable white offenders and [demonetizing LGBTQ+ content on YouTube](https://www.vox.com/culture/2019/10/10/20893258/youtube-lgbtq-censorship-demonetization-nerd-city-algorithm-report) ostensibly based on benign word choices in video descriptions. In the US, concern has also grown around the use of these systems by social media sites to [spread misinformation and radicalizing content](https://www.cbsnews.com/news/facebook-whistleblower-frances-haugen-misinformation-public-60-minutes-2021-10-03/) on their platforms, and the [safety of self-driving cars](https://www.nytimes.com/2018/03/19/technology/uber-driverless-fatality.html) continues to be of concern.
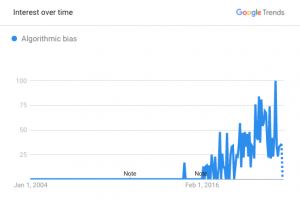
Google Search trend for ‘algorithmic bias’ from 2000 to 2021.
Along with this swell of public awareness has emerged a growing chorus of voices (such as [Joy Buolamwini](https://www.media.mit.edu/people/joyab/overview/), [Sandra Wachter](https://www.oii.ox.ac.uk/people/sandra-wachter/) and [Margaret Mitchell](http://m-mitchell.com/)) advocating for fairness, transparency and accountability in the use of machine learning. Corporations appear to be starting movement in this direction as well, though not without [false starts](https://www.bloomberg.com/news/articles/2021-02-18/google-to-reorganize-ai-teams-in-wake-of-researcher-s-departure), controversy and a lack of clarity on how to operationalize their often lofty, well-publicized AI principles.
From one corner of these conversations an interesting thought has begun to emerge: that these problems are [neither new, nor novel to ML](https://towardsdatascience.com/the-present-and-future-of-ai-regulation-afb889a562b7). And, in fact, institutions already have a well-honed tool to help them navigate this space in the form of organizational risk governance practices. Risk governance encompasses the “…institutions, rules conventions, processes and mechanisms by which decisions about risks are taken and implemented…” ([Wikipedia, 2021](https://en.wikipedia.org/wiki/Risk_governance)) and contemplates broadly all types of risk, including financial, environmental, legal and societal concerns. Practically speaking, these are often organizations within institutions whose goal it is to catalogue and prioritize risk (both to the company and that which the company poses to the wider world), while working with the business to ensure they are mitigated, monitored and/or managed appropriately.
Image Copyright
It stands to reason then that this mechanism may also be leveraged to consider and actively manage the risks associated with deploying machine learning systems within an organization, helping to [close the current ML accountability gap](https://dl.acm.org/doi/pdf/10.1145/3351095.3372873). A goal which might seem more within reach when we consider that the broader risk management ecosystem (of which risk governance forms a foundational part) also includes standards (government regulations or principles-based compliance frameworks), corporate compliance teams that work directly with the business, and internal and external auditors that verify sound risk management practices for stakeholders as diverse as customers, partners, users, governments and corporate boards.
This also presents an opportunity for legacy risk management service providers, such as [PwC](https://www.pwc.com/gx/en/issues/data-and-analytics/artificial-intelligence/what-is-responsible-ai.html), as well as ML-focused risk management startups like [Monitaur](https://monitaur.ai/) and [Parity](https://www.getparity.ai/) to bring innovation and expertise into institutional risk management practices. As this ecosystem continues to evolve alongside data science, research and public policy, risk governance stands to help operationalize and make real organizational principles, and hopefully lead us into a new era of accountability in machine learning.
A New Development in Autoimmune Disease Research By Anonymous | October 8, 2021
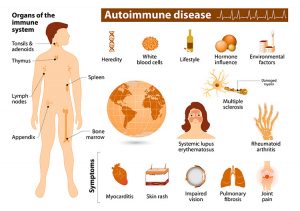
Autoimmune Diseases at a Glance | Source: https://www.niehs.nih.gov/health/topics/conditions/autoimmune/index.cfm
Autoimmune diseases are a class of diseases that have perplexed researchers and medical experts for decades. Autoimmune diseases affect over 15 million people in the United States and are prevalent among women between 20-40 years old [1]. With over 150 diseases and 40 subtypes that are characterized by a wide range of symptoms, it is often difficult to recognize that a patient has an autoimmune disease or diagnose the patient with a specific autoimmune disease [1]. In November 2020, the Autoimmune Registry, Inc. (ARI) released the first comprehensive list of autoimmune diseases based on data they have been collecting through a voluntary registry where individuals with autoimmune diseases can enter the details about their disease diagnosis. As someone who was recently diagnosed with an autoimmune disease after years of unexplained symptoms and shoulder shrugs from doctors who were unfamiliar with the markers of an autoimmune disease, I was eager to learn more about this registry and how I could use it for my own education. Beyond that, as a data scientist, I was particularly interested in the methods in which the ARI protects user data and how that data is being utilized in research studies.
What is an Autoimmune Disease?
What causes an Autoimmune Disease? | Source: https://visual.ly/community/Infographics/health/understanding-autoimmune-disease
An immune system that functions normally has the ability to recognize and fight off viruses, bacteria, and other foreign substances that could potentially result in disease or illness. An autoimmune disease is characterized by an overactive immune system that mistakes healthy tissues and cells within the body for harmful substances and creates antibodies to attack them [8]. Autoimmune diseases have a variety of possible causes, the most common of which are: genetics, environmental factors, infectious disease, and lifestyle choices. Individuals with a family history of autoimmune disease are at a greater risk for developing that disease than the general population. Autoimmune diseases can also develop when an individual’s immune system is compromised during an illness as the result of a bacterial or viral infection. Environmental factors such as exposure to harmful chemicals or toxins, lack of exposure to sunlight, and vitamin D deficiency have been linked to the development of autoimmune diseases [8]. Lifestyle choices like smoking, an unhealthy diet, and obesity have been shown to put an individual at a much higher risk of developing an autoimmune disease in their lifetime [8].
There are many different autoimmune diseases and many of them have overlapping symptoms. The most common symptoms among autoimmune disease are fatigue, joint pain, weight loss or weight gain, dizziness, and digestive issues [8]. The wide variety of symptoms that often overlap with other autoimmune diseases or conditions make diagnosing an autoimmune disease extremely difficult. Among the most commonly recognized and diagnosed autoimmune diseases are Type 1 Diabetes, Rheumatoid Arthritis, Multiple Sclerosis, Celiac Disease, and Lupus [5]. For most autoimmune diseases, there is no cure and treatment is focused on mitigating symptoms and preventing disease progression.
Privacy Policy for the Autoimmune Registry
Autoimmune Registry Rules of Participation | Source: https://survey.autoimmuneregistry.org
Before an individual can enroll in the registry on the ARI website, they have to register as a user and agree to the rules for participation for the registry. Shown in the visual above, the rules give the individual details regarding how their data will be stored and used. The registry’s primary goal is to find participants for research studies and clinical trials for treatments for autoimmune diseases such as lupus.
The data entered into the registry is categorized into Personally Identifiable Data (PID) and Non-Identifiable Data (NID). The rules don’t specify exactly what data constitutes PID versus NID but based on the subsequent information provided, it can be inferred that PID refers to name, mailing address, phone number, email address, etc. NID is information voluntarily given to the registry regarding the specifics of the user’s autoimmune disease and symptoms. The NID is anonymized and entered into a database that researchers can query to find potential study or clinical trial participants.
If a user fits the criteria for a research study, the ARI will contact the user on behalf of the researcher with information about the study. The ARI emphasizes that if a user receives an email regarding a study that they “are telling **you** about the **study**,” and “**have NOT told the people running the study about you**,” [2]. Participation is completely voluntary and if a user decides they want to be part of the research, they need to contact the researcher directly. It is further stated that the ARI will never give PID out to a researcher or organization unless they receive explicit written permission from the user.
Having said that, the ARI explains that user data is not protected under the Health Insurance Portability and Accountability Act (HIPAA) since the ARI is not considered a protected entity under HIPAA. The ARI uses HIPAA and other patient privacy laws as the framework for their privacy policy and adhere to those guidelines as much as possible when handling user PID and health related data. By consenting to the privacy policy of the registry, the user is acknowledging that their data may not have the same protections as health data stored in their medical records or other locations.
A user has the ability to modify their PID within the registry but the privacy policy states that the ARI will retain the old PID in backup files and will not destroy those files even if a user requests that their information be permanently erased. It is not clear why the ARI maintains the old PID on file but regardless of the reason, they assure users that their backup files are protected to prevent unauthorized access. The privacy policy concludes by stating that the ARI bears no responsibility if user data is illegally accessed. This statement gave me pause as a potential user of the registry since illegal access of my PID and other health data would in many cases be the result of insufficient data protection or storage and I would expect that an organization would take some measure of responsibility if their system of protection was compromised.
Researcher Access to Registry
For a researcher to access the registry, they must submit a formal request to the ARI. This request includes a research application that requires the researcher to submit professional references and evidence that the research they have previously conducted had a direct impact on patients [4]. The researcher must also complete online training concerning the protection of human subjects and submit a research proposal to the ARI. This proposal will justify the researcher’s need for access to the registry. As a potential user of the registry, I was glad to read that the ARI is selective with who they allow access to the registry. I feel more comfortable knowing that only legitimate researchers interested in studying autoimmune diseases will have the ability to view data within the registry and that any contact I would receive about study participation would be from a reputable source.
User Registration for the Registry
After reading through the rules of participation for the registry, I made the decision to move forward with the registration process. Partly because I was curious to see what questions would be asked and you have to create an account to see said questions but also because I want to learn more about my own health and treatments that are in development or available.
The first section of questions asked for basic demographic information: address, gender, height, and weight. After those questions were complete, a list of autoimmune diseases was displayed and I was instructed to select which autoimmune disease or diseases I had been diagnosed with. Following my selection, the next set of questions asked about when I was diagnosed with the autoimmune disease and whether I would be willing to provide hair, saliva, or blood samples to the registry for research use. This question caught me off guard because there was no mention of collection or storage of biological data in the privacy policy. Based on the language of the privacy policy, I assumed that the only purpose the registry served was as a means of compiling aggregated data of autoimmune disease demographics and allowing researchers to recruit participants for studies and trials. There was no mention of the ARI independently collecting biological data for any purpose within the privacy policy or anywhere on the website that I could find so I declined to provide those samples until I can obtain more information on their storage and use.
Finally, the registration asked me if I would be interested in receiving emails from the ARI regarding developing research on my autoimmune disease and potential opportunities for research participation. I was also asked if I would be interested in sharing my story on social media, another surprising question considering there was no mention of social media usage within the privacy policy. I declined to participate in social media since adequate information regarding what that participation would entail was not provided.
Final Thoughts
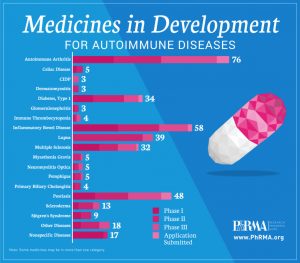
Treatments in Development | Source: https://www.statnews.com/sponsor/2017/03/17/new-innovative-medicines-offer-hope-autoimmune-disease-patients-2/
For many people searching for answers or treatments for their autoimmune disease, the Autoimmune Registry is a blessing. The research studies enabled by the registry through the connection of researchers to participants have the potential to result in the discovery of new autoimmune diseases and treatments for existing ones. The information found may also give both patients and medical professionals greater insights into treatments and prognosis associated with different autoimmune diseases. As a data scientist, I was less than thrilled at the privacy policy provided by the registry. The ARI would benefit from expanding their privacy policy to include information about the collection and storage of biological data as well as potential social media participation for registered users. But as someone who would personally benefit from these discoveries, I am thankful that a registry like this exists and am willing to participate in future studies to find treatments for myself and others suffering from autoimmune diseases.
References
[1] Autoimmune Registry, Inc. (2020, November 18). The Autoimmune Registry releases first complete list of autoimmune diseases with prevalence statistics, disease subtypes, and disease profiles. _Cision US Inc._ Retrieved October 6, 2021 from https://www.prnewswire.com/news-releases/the-autoimmune-registry-releases-first-complete-list-of-autoimmune-diseases-with-prevalence-statistics-disease-subtypes-and-disease-profiles-301176322.html.
[2] Autoimmune Registry, Inc. (n.d.). Patient privacy. _The Autoimmune Registry._ Retrieved October 7, 2021, from https://www.autoimmuneregistry.org/new-page-2.
[3] Autoimmune Registry, Inc. (n.d.). Participant Registration and Login. _The Autoimmune Registry._ Retrieved October 7, 2021, from https://survey.autoimmuneregistry.org.
[4] Autoimmune Registry, Inc. (n.d.). Become a Researcher. _The Autoimmune Registry._ Retrieved October 7, 2021, https://www.autoimmuneregistry.org/for-researchers
[5] Diabetes Digital Media, Ltd. Autoimmune disease refers to illness or disorder that occurs when healthy tissue (cells) get destroyed by the bodys own immune system. Diabetes. Retrieved October 8, 2021, from https://www.diabetes.co.uk/autoimmune-diseases.html.
[6] NewLifeOutlook. (2021, April 15). Understanding autoimmune disease. _Visual.ly._ Retrieved October 8, 2021, from https://visual.ly/community/Infographics/health/understanding-autoimmune-disease.
[7] PhRMA. (2017, March 17). New and innovative medicines offer hope to autoimmune disease patients. _STAT._ Retrieved October 8, 2021, from https://www.statnews.com/sponsor/2017/03/17/new-innovative-medicines-offer-hope-autoimmune-disease-patients-2/.
[8] Shomon, M. (2021, August 2). What are autoimmune diseases? _Verywell Health._ Retrieved October 8, 2021, from https://www.verywellhealth.com/autoimmune-diseases-overview-3232654.
[9] U.S. Department of Health and Human Services. (2021, July 12). Autoimmune diseases. _National Institute of Environmental Health Sciences._ Retrieved October 8, 2021, from https://www.niehs.nih.gov/health/topics/conditions/autoimmune/index.cfm.
The Facebook Whistleblower and the Moral Dilemma By Anonymous | October 8, 2021
In a span of three days, Facebook broke the internet literally and figuratively. On October 4, 2021, three of the most popular platforms globally – Facebook, Instagram, and WhatsApp – were offline for multiple hours. A 60 Minutes episode aired the night before, interviewing data scientist and former Facebook product manager France Haugen. She claimed that Facebook and its products harm children and stoke division with hate, violence, and misinformation. She then testified to Congress on October 5, 2021, mainly blaming Facebook’s algorithm and platform design for these issues.
Who is Frances Haugen and What Exactly Does She Claim?
Now famously known as the “Facebook Whistleblower,” Frances Haugen was hired in 2019 to work as a product manager for the Civic Integrity team, a team to tackle misinformation and hate speech. When this team was dissolved a month after the 2020 U.S. Election, she started to see the company’s harmful effects and immoral compass. Before leaving Facebook in May 2021, she retrieved thousands of internal research documents that she used in her claims in the 60 Minutes interview and congressional testimony. With her evidence, Haugen claimed the platform’s algorithms and engagement-based ranking system harm societies worldwide, and that leadership knew about this but did not act on it. In addition, she provided research stating that the algorithms majorly impact children and teens. For example, children could start looking for healthy recipes on Instagram and end up on pro-anorexia content, causing them to feel more depressed. Other research suggests that Facebook’s algorithms have led European countries to adopt more extreme policymaking and to cause ethnic violence around the world, like Myanmar’s military using the platform to launch a genocide campaign.
How do Facebook’s Algorithms and Ranking System Work?
Facebook’s machine learning algorithms and engagement-based ranking system aim to have personalized content by using information such as clicking on advertisements and liking/sharing posts. The algorithm takes these data points to predict what posts and advertisements users might also be interested in. But when platforms blend content personalization and algorithmic amplification, “they create uncontrollable, attention-sucking beasts,” leading to perpetuating biases and affecting societies in ways barely understood by their creators. But in this specific case, Facebook’s leadership knew of the harmful effects and did not act on making the platform a safer place for their financial gain. The algorithm rewards posts that entice the most extreme emotions (often anger, rage, or fear) because it is designed to keep users on the platform for as long as possible, no matter how it makes them feel or what it makes them think. The longer a user is on the platform, the more likely they will click on ads, leading to more revenue for the company.
What Protects Facebook from Legal Action?
Section 230 of the U.S. Communications Decency Act, passed in 1996, prevents online platforms from being responsible for any third-party content being shared on the platforms. Haugen’s proposal to Congress is reforming section 230 around algorithmic ranking, so online platforms like Facebook will be held responsible for their decisions and actions around personalized algorithmic amplification.
The Moral Dilemma: What Would You Do?
A moral dilemma is a “conflict situation in which the choice one makes causes moral harm, which cannot be easily repaired if at all.” There is a long history of companies choosing profit over safety (I tried to narrow down some significant examples, but there are too many to list). With more and more companies using data science for decision-making, data scientists often get caught in the middle of a moral dilemma: doing what they’re told by leadership, possibly knowing the harm that will come from these decisions from leadership. It is hard to predict what someone would do if they were in Haugen’s position. We generally aim to do the right thing, but it becomes a more complicated question when you jeopardize your source of income that provides for yourself and your family.
We as data scientists may face dilemmas like Frances did, where the work we do and the companies we work for might not have the best moral compass. Facebook has approximately 2.9 billion monthly active users – 60 percent of all internet-connected people on the planet – and Frances Haugen spoke up about the unethical practices taking place on the platform. Not many people could have done what she did, and I applaud her for standing up to one of the largest companies and platforms in the world.
It is Time to Revisit HIV Public Health Practices By Jackie Nichols | October 7, 2021
For over 15 years, I’ve been working with organizations whose mission is to end AIDS. My passion stems from growing up in the 1980’s when the deadly disease became its most prominent and fear gripped us all. Stories that I had been reading about or seeing on the news became a part of my life. Several of my friends had contracted AIDS and sadly lost their lives to the disease. As we learned more about the disease, fear subsided, and I fell trap to naively believing that AIDS was a thing of the past. It wasn’t until years later that a friend asked for a donation for the 2006 NY AIDS walk that I realized my naivety. I had managed to push the uncomfortable topic of HIV/AIDS out of my thoughts since the disease was no longer as prominent in my day-to-day life. I was also shocked that AIDS hadn’t been defeated yet and that there was so much more work to do. Work that centered around public health practices.
Public Health
The CDC estimates there are as many as 1.2 million Americans infected with HIV with approximately thirteen percent of them unaware (U.S Statistics, 2021). In Los Angeles alone, it’s estimated that a quarter of all people diagnosed with AIDS during 1990 – 1995 only became aware of their infection when they exhibited advanced symptoms and received care at a hospital or clinic (Burr, 1997). This would mean that they would have most likely been HIV-positive for years and perhaps spreading the disease unknowingly. While it’s true that an HIV-positive patient will require a lifetime of costly treatment, estimated at $4,500 each month per patient (How Much Does HIV Treatment Cost?, 2020), it’s the CDC’s belief that even just one notification out of eighty pays for itself by preventing any new HIV infections (Burr, 1997). With HIV being treatable, it seems like we should be doing more to test for the disease and notify others as early as possible. Imagine the outrage if the US stopped routine testing for breast, ovarian or colon cancer and only treated patients upon admission to a hospital due to exhibiting advanced symptoms.
Contact Tracing
If you didn’t know what contact tracing was before the pandemic, there’s a good chance you know now. I’m sure most of us have heard public officials say that we must do our part to “flatten the curve” when referring to the COVID-19 pandemic. Flattening the curve refers to keeping the number of reported COVID-19 cases as low as possible, accounting for the load on our health care system. Contact tracing is one process that can help flatten the curve by identifying persons who may have come in contact with an infected person (“contacts”) and subsequent collection of further information about these contacts.
Figure 1 COVID-19 Contact Tracing
The goal of contact tracing is to reduce infections in the population by tracing the contacts of infected individuals, testing the contacts for infection, and isolating or treating the infected, and then tracing their contacts. Contact tracing is just one measure against an infectious disease outbreak and often requires some of the following steps be taken in conjunction: routine testing and in most cases without explicit patient consent, reporting the names of those who test positive to local health authorities, and notification to those that were in contact with the infected person that they may been exposed to. Those being notified should receive only the information they really need to maintain the privacy and anonymity of the infected individual.
Contact tracing isn’t new. In fact, it’s been used for centuries and has been one practice in the fight against infectious disease outbreaks that include tuberculosis, diphtheria, typhoid and now COVID-19. It’s intriguing that HIV, an epidemic responsible for more than an estimated 700,000 deaths in the US since 1981 (Cichocki, 2020), isn’t routinely tested for, and when it is it requires explicit patient consent. The names of those who do test positive for HIV are not reported to local health authorities making contact tracing impossible.
Why Do We Treat HIV so differently?
To understand why testing, contact tracing and notification for HIV/AIDS is so different from other infectious diseases, we need to look back to the 1980’s and at what drove the ignorance and fear through four very common beliefs (Burr, 1997):
The disease was first called Gay-Related Immune Deficiency (GRID) by researchers leading the public to believe that AIDS was limited to homosexuals and in fact a marker of homosexuality.
The stigma associated with AIDS and how the disease is transmitted would make it impossible to maintain any level of testing confidentiality.
There was a limited understanding of how the disease was spread with sexual transmission believe to be the only method. It was believed that HIV is only transmitted through sex, which is a taboo subject in some cultures. With the stigma associated with people who contracted AIDS, it was felt that contact tracing would be ineffectual due to the large number of sexual partners of those infected.
AIDS was so different and limited to who it affected, with no cure or treatment, it was believed that it would be pointless to report HIV infection as is done for other infections. There was an early belief that the disease would “run its course”.
The damage of these four beliefs was significant and is still felt to this day. While many in the US have learned and believe that the disease is not a homosexual marker, testing, contact tracing along with privacy and stigma remain as challenges.
Testing for HIV
Being admitted to any hospital or ER today in the US typically involves patient blood work that is tested for various diseases (e.g., tuberculosis) as well as the patient being tested for COVID-19. The blood work and COVID-19 tests occur without patient consent and are generally an accepted societal norm, i.e., people do not question that they will be tested when being admitted to a hospital. Similarly, a lot of work has been undertaken to reach similar norms for yearly wellness checks for women to test for breast and ovarian cancer, and for routine checks for colon cancer in the general population. According to Nisenbaum, this is what she refers to as contextual integrity; privacy holds when context-relative informational norms are respected; it is violated when they are breached (Nissenbaum, 2008).
Unlike other infectious diseases, testing for HIV requires explicit patient consent and is currently prohibited in every state. Blood banks are the exception as they test and screen for HIV but do not perform notifications should a sample be found to be infected. Blood banks maintain privacy by following existing legislation and social norms but in doing so, potentially allow the spread of the disease to continue. Interestingly, AIDS infections must be reported in all fifty states, but HIV does not have the same requirement once again skirting the proven methods of tracing infectious diseases. For those states that do report HIV-positive results, all personal information is removed from the test results prior to sending to the Centers for Disease Control and Prevention (CDC) to monitor what is happening with the HIV epidemic.
Partner Notification
The CDC has various outreach efforts that they refer to as “Partner notification” which includes contact tracing. This involves patients volunteering for a test, and public-health officials locating and notifying partners of infected people of possible infection. This process hinges on people being willing or able to share the names of their partners. Privacy is maintained by keeping the infected patients name confidential, although that does not always guarantee anonymity. In most states there is no legal obligation to disclose your HIV-positive status to your current or past partners (Privacy and Disclosure of HIV Status, 2018).
Figure 2 HIV Partner Notification
The goal with HIV partner notification is to minimize the spread of the disease, and to treat the disease as early as possible before reaching the late stage of AIDS. AIDS is stage 4 and typically occurs when the virus is left untreated. The earlier the virus is detected, the more manageable the disease for the individual through antiretroviral drugs. Partner notification requires two things to be successful: people must be willing to be tested and provide the results, and people must be able to act on the information. For this to happen at a scale needed to combat HIV, the privacy of the infected individuals must be protected from unnecessary disclosure. With the data breaches that plague our digital world, one’s privacy isn’t a guarantee making HIV contact tracing more challenging than other infectious diseases.
The Impact of Stigma on HIV Public Health Policies
Stigma is one of, if not the biggest blocker from mandating HIV and AIDS testing and reporting in advancing the public health policies around HIV. Whenever AIDS has won, stigma, shame, distrust, discrimination and apathy was on its side (HIV Stigma and Discrimination, 2019). HIV stigma refers to irrational or negative attitudes, behaviors, and judgments towards people living with or at risk of HIV (Standing Up to Stigma, 2020). When people are identified as HIV-positive there is a risk of being stigmatized and being discriminated against. Some of the beliefs that originated in the 1980’s still exists and in some areas in the US, thrive, e.g., HIV/AIDS is a homosexual marker. While we have made progress in gay rights and equality, being identified as a homosexual can still lead to harassment, discrimination, abuse, and violence. People are aware of the stigma and the risk associated with being publicly identified as HIV-positive and as a result many people avoid accepted public health practices like testing and reporting when it comes to HIV. In the 1980s and 1990’s the driving force for many of the legal cases involving protecting the privacy of patients was driven by the stigma associated with AIDS and the risk of being publicly identified as HIV-positive. While section 504 of the Rehabilitation Act of 1973 and Disabilities Act of 1990 (ADA) were updated to protect the civil and workplace rights of people living with HIV and AIDS (Civil Rights, 2017), many people still feel it’s not enough given the power of societal judgement and the way harassment and abuse can manifest itself causing harm to the infected individual. As a result, we are left with HIV being exempt from consent free testing and reporting, only requiring that AIDS be reported in all fifty states, and a disease that is allowed to go undetected and untraced potentially harming others unknowingly.
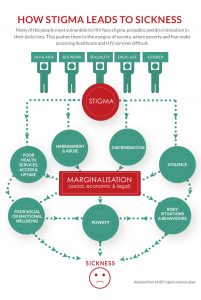
Figure 3 How Stigma Leads to Sickness
Closing Thoughts
Forty years later, it’s clear that when addressing the issue of HIV and public health practices stigma plays a significant role. When considering the broader public health question of how you can control a disease if you decline to find out who is infected (Shilts, 1987) is at the core of the battle to end AIDS. It’s clear that we must first defeat the HIV stigma which will allow for the implementation of better public health practices that are needed to end AIDS.
Model Cards for Transparency By Anonymous | October 8, 2021
In February of 2019, OpenAI wrote a blog post discussing results of their GPT-2 model (Radford et al., 2019). According to the release,
We’ve trained a large-scale unsupervised language model which generates coherent paragraphs of text, achieves state-of-the-art performance on many language modeling benchmarks, and performs rudimentary reading comprehension, machine translation, question answering, and summarization – all without task-specific training. -OpenAI
What makes the release of this model unique from an AI and data ethics perspective is that OpenAI decided not to release the model at that time and opened the blog by saying they would not do so because they were concerned about malicious uses of the technology. Examples of malicious uses were textual deep fakes; in other words, the ability of GPT-2 to give results that could reasonably appear to be human generated. The fact that the researchers purposefully chose to articulate malicious use cases and attempt an “experiment in responsible disclosure” (Radford et al., 2019) was a divergence then and continues to be a divergence from the common pattern of releasing machine learning models for end users to consume without making those users aware of ethical implications.
Robot Hands Typing
In January 2019, Margaret Mitchell and colleagues presented the paper Model Cards for Model Reporting at the Fairness, Accountability and Transparency (FAT*) conference (Mitchell et al., 2019). The key point of the paper is that machine learning systems have been found to have systemic bias and that bias is usually found by a human being that is affected by the bias inherent in the model. By releasing models with model cards which provide information such as: who created the model, when and with what software was the model created, what are the intended use cases, what training and evaluation data was used, what ethical considerations and caveats should be taken with the model, different users of the model can make an informed decision about whether it fits their use case without needing to seek out this additional information on their own.
Examples in the paper of people who could make use of the model cards are machine learning researchers, software engineers and policymakers. GPT-2 ( https://github.com/openai/gpt-2/blob/master/model_card.md), and its later evolution (https://github.com/openai/gpt-3/blob/master/model-card.md).
In particular with regulation for AI underway by governments like the EU and Brazil, it will be important to have a way to evaluate whether artificial intelligence algorithms are meeting the standards set by law and for companies to comply with the law. Modified model cards which display legal requirements and how the model complies helps identify whether a model meets the requirements. Further, while responsible and ethical AI is a huge topic, it is much better to have a model card which states ethical considerations than having to discover on one’s own. While in a perfect world the model cards would be generated automagically when the model is trained and the model would be required to meet certain metrics based on curated datasets, aspects of model cards, such as ethics and caveats, cannot be automated. Since at least some large companies will use AI models in multiple regulatory environments, the model cards will also serve as a way for the companies to keep track of how their models are performing in these different environments.
While the initial release of GPT-2 made a great step toward early identification of potential misuses of the model, searching for model cards on any of the large cloud providers yields almost no results in spite of the fact that customers are easily able to call cognitive services (image recognition, object detection, a wide range of natural language processing functions) it is left as an exercise for the user to identify what the ethical and policy implications of using the model is. Model cards as suggested by Mitchell et al. would help intentional users (people implementing the model) and unintentional users (the public or user of a product) have a much better understanding of the characteristics of the black box AI model.
References
Alec Radford, J. W. (2019, February 14). Better Language Models and Their Implications. Retrieved from OpenAI: https://openai.com/blog/better-language-models/
Margaret Mitchell, S. W. (2019, 1 14). Model Cards for Model Reporting. Retrieved from Arxiv.org: https://arxiv.org/pdf/1810.03993.pdf