Impact of Algorithmic Bias on Society
By Anonymous | December 11, 2018
Artificial intelligence (AI) is being widely deployed in a number of realms where they have never been used before. A few examples of areas in which big data and artificial intelligence techniques are used are selecting potential candidates for employment, decisions on whether a loan should be approved or denied, and using facial recognition techniques for policing activities. Unfortunately, AI algorithms are treated as a black box in which the “answer” provided by the algorithm is presumed to the absolute truth. What is missed is the fact that these algorithms are biased for many reasons including the data that was utilized for training it. These hidden biases have serious impact on society and in many cases the divisions that have appeared among us. In the next few paragraphs we will present examples of such biases and what can be done to address them.
In her book titled, “Weapons of Mass Destruction”, a mathematician, Cathy O’Neil, gives many examples of how mathematics on which machine learning algorithms are based on can easily cause untold harm on people and society. One such example she provides is the goal set forward by Washington D.C.’s newly elected mayor, Adrian Fenty, to turn around the city’s underperforming schools. To achieve his goal, the mayor hired an education reformeras the chancellor of Washington’s schools. This individual, based on an ongoing theory that the students were not learning enough because their teachers were not doing a good job, implemented a plan to weed out the “worst” teachers. A new teacher assessment tools called IMPACT was put in place and the teachers whose scores fell in the bottom 2% in the first year of operation, and 5% in the second year of the operation were automatically fired. From mathematical sense this approach makes perfect sense: evaluate the data and optimize the system to get the most out of it. Alas, as Cathy points out in the example, the factors that were used to determine the IMPACT score were flawed. Specifically, it was based on a model that did not have enough data to reduce statistical variance and improve accuracy of the conclusions one can draw from the score. As a result, teachers in poor neighborhoods, performing very well in a number of different metrics, were the ones that were impacted by the use of the flawed model. The situation was further exacerbated by the fact that it is very hard to attract and grow talented teachers in the schools in poor neighborhoods, many of whom are underperforming.
Gender Bias in Algorithms Used By Large Public Cloud Providers
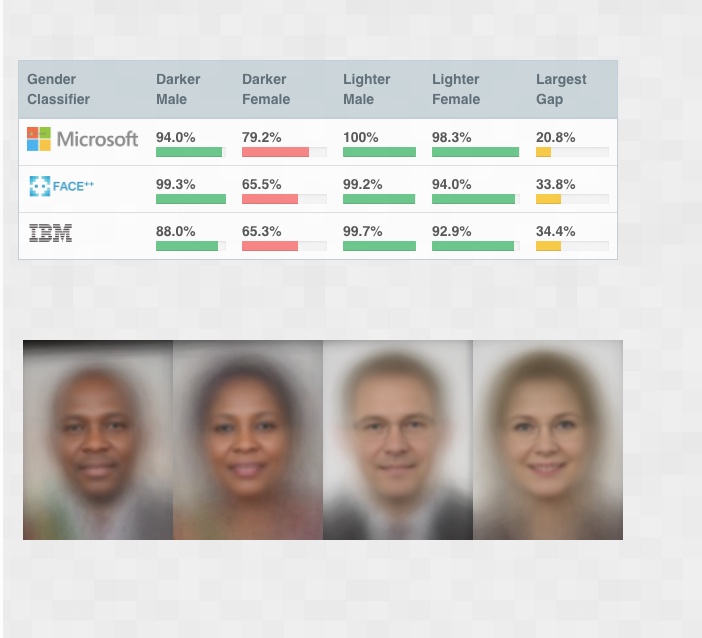
The bias in algorithms is not limited to small entities with limited amount of data. Even large public cloud providers with access to large number of records can easily create algorithms that are biased and cause irreperable harm when used to make impactful decisions. The website, http://gendershades.org/, provides one such example. The research to determine if there were any biases in the algorithms of three major facial recognition AI service provider— Microsoft, IBM and Face++— was conducted by providing 1270 images from a mix of individuals originating from the continent of Africa and Europe. The sample had subjects from 3 African countries and 3 European countries with 54.4% male and 44.6% female division. Furthermore, 53.6% of the subjects had light skin and 46.4% had darker skin. When the algorithms from the three companies were asked to classify the gender of the samples, as seen in the figure below, the algorithms performed relatively well when one looks just at the overall accuracy.

However, on further investigation, as seen in the figure below, the algorithms performed poorly when classifying dark skinned individuals, particularly women. Clearly, any decisions that one makes based on the classification results of these algorithms, would be inherently biased and potentially harmful to dark skinned women in particular.
Techniques to Address Biases in Algorithms
The recognition that the algorithms are potentially biased is the first and the most important step towards addressing the issue. The techniques to use to reduce bias and improve the performance of algorithms is an active area of research. A number of techniques ranging from creation of an oath similar to the Hippocratic Oath that doctor’s pledge to a conscious effort to use a diverse set of data much more representative of the society has been proposed and is being evaluated. There are many reasons to be optimistic that although the bias in algorithms can never be eliminated, in the very near future the extent of the bias in the algorithms would be reduced.
- Cathy O’Neil, 2016, Weapons of Math Destruction, Crown Publishing Company.
- How well do IBM, Microsoft and Face++ AI services guess the gender of a face?