Does cashless society discriminate against the poor and elderly?
By Adara Liao | October 13, 2019
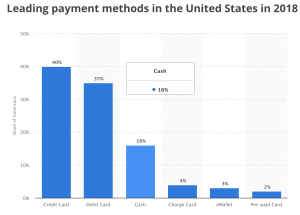
The increasing prevalence of cashless payments, including mobile phone payments, digital payments and credit cards, in the world means that cash circulation is dropping worldwide. Some retailers do not accept cash or incentive customers to pay using smartphones. In major cities in China, over 90 percent of people use WeChat and Alipay as their primary payment method, ahead of cash. In the US, the use of cash is just 16% of total transactions and is expected to decline as cards growth accelerate.
The growing use of cashless payment puts financially disenfranchised populations at a disadvantage as they cannot participate in services that require cashless payments and pay higher cost when transacting in cash.
Two populations who are less likely to participate in cashless payments are the elderly and the poor. The elderly are less able to manage cashless payment methods, especially without transition support. If local authorities or utility companies do not support cash, the elderly cannot get their government subsidies and face hurdles to pay for basic services.
In some countries, retailers may charge more for accepting cash or refuse cash payments altogether. In the US, many restaurants refuse to accept cash due to combination of incentives from credit card networks like Visa and Mastercard and desire to create a frictionless experience for high-value customers. For those who do not qualify for cards, or cannot afford mobile payment methods, they are excluded from these retailers.
In addition to being locked out of retailers, low-income people who participate in cashless payments options face stiff penalties for overdraft fees from their savings accounts and are ineligible to receive credit cards who reward wealthy users for money spent. People who rely on cash subsidize wealthier people who use credit cards.
About a third of the population in the US are underbanked, which means they opt to go without regular patronage of traditional money management services such as debit cards and checking accounts. Traditionally, possessing a bank account is required for participation in digital payment services. Although startups now act as savings accounts with low fees that replace traditional bank accounts, they do not have brick and mortar presence of traditional banks and require digital literacy which will still exclude the lowest segments of underbanked and poor. Thus, there is a population who require cash and need to be addressed by retailers and companies.
Governments can protect financial inclusion for people who are unable to participate digitally. In the US, The Cashless Retailers Prohibition Act of 2018 would make it illegal for restaurants and retailers not to accept cash or charge a different price to customers depending on the type of payment they use. Education can also play a part in helping elderly adopt digital payments. In Singapore, the government holds classes to help its senior population learn how to use digital payments such as paying in store using QR codes and topping up travel cards with debit cards [1].
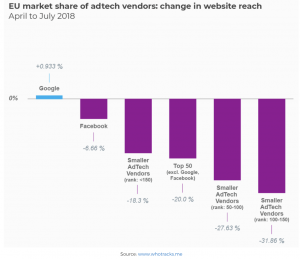
It is not just tech-disadvantaged populations who are vulnerable to discriminatory actions in a cashless society. Fintech companies have access to a broader set of information on a customer’s financial habits and social network. Such information provides fintech companies with power to make lending decisions, or partner with credit-scoring or lenders to make discriminatory decisions.
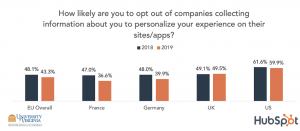
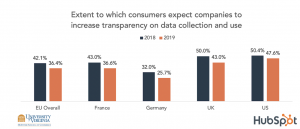
With more information collected by fintech companies, consumers’ preferences can be shared with third parties or sold for profit. To the extent that fintech companies are susceptible to hacking or undisciplined sharing of consumers’ information with third parties, the privacy of consumers are compromised. Thus, sensitive information about consumers should be regulated and consumers have to be clearly informed about how and who will use their information.
As society moves towards cashless payments, groups without the financial ability or adoption ability to participate in cashless payments risk being put at a disadvantage. Possessing high-end smartphones, qualifying for debit cards and having the technological know-how to operate cashless payments methods safely are barriers to entry for disenfranchised groups. To ensure that all groups in society are able to fully participate in the changing landscape, governments can introduce laws to protect cash acceptance and be mindful of impact on disenfranchised groups when encouraging fintech industry.
References
[1] https://www.raconteur.net/finance/financial-inclusion-cashless-society
[2]https://www.theguardian.com/business/2018/jul/15/cashless-ban-washington-act-discrimination
[3]https://www.brookings.edu/wp-content/uploads/2019/06/ES_20190614_Klein_ChinaPayments_2.pdf
[4]https://www.brookings.edu/opinions/americas-poor-subsidize-wealthier-consumers-in-a-vicious-income-inequality-cycle/
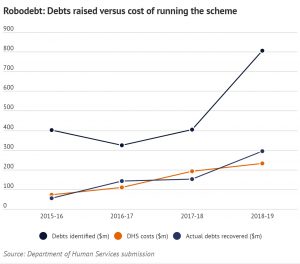
Chart Source
[1] https://www.statista.com/statistics/568523/preferred-payment-methods-usa/
[2]https://www.emarketer.com/content/four-mobile-payment-trends-to-watch-for-in-2019