Facebook Fined $5 Billion for Data Privacy Violations – Was It Enough?
By Anonymous | November 1, 2019
On July 24, 2019 the U.S. Federal Trade Commission (FTC) announced a $5 billion penalty levied on Facebook for consumer data privacy violations. It was by far the largest privacy-related fine imposed by any entity.
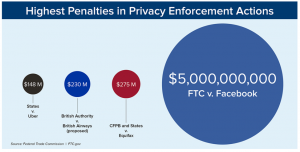
Figure 1: Relative Penalties in Privacy Enforcement Actions
The FTC’s announcementexplained that the penalty was in response to Facebook deceiving their platform users about users’ ability to control the privacy of their personal information, a direct violation of a 2012 FTC order against Facebook.
The latest FTC probe of Facebook was precipitated by the highly-publicized Cambridge Analytica scandal, which was widely exposed in March 2018 and involved the exploitation of personal data from up to 87 million Facebook users. The Cambridge Analytica case illustrated the extent to which Facebook deceived its users regarding the control and protection of the users’ personal information, by undermining users’ privacy preferences and failing to prevent third-party applications and data partners from misusing users’ data. Facebook was aware of the policy violations, and these tactics allowed Facebook to share users’ personal information with third-party apps that were downloaded by users’ Facebook “friends.” The FTC also flagged other Facebook failures, such as misleading tens of millions of users about their ability to control facial recognition within their accounts, despite assurances to the contrary in Facebook’s April 2018 data policy. Facebook also failed to disclose it would use users’ phone numbers for advertising purposes when users were told it needed their phone numbers for two-factor authentication.
Despite the unprecedented amount of the fine, which represented about 9% of Facebook’s 2018 revenue, many thought it did not go far enough. The FTC committee in charge of this case was split 3-2 along party lines, with the two Democrats on the committee stating that the penalty should have been larger. Others characterized the fine as a “slap on the wrist”. The fact that the stock price ticked up immediately after the announcement indicated that the market was expecting a larger penalty than what was imposed.
In addition to the monetary penalty, the FTC order placed certain restrictions on Facebook’s business operations and created new compliance requirements, all in an attempt to change the company’s consumer privacy culture and prevent future failures. The FTC required Facebook to “establish an independent privacy committee of Facebook’s board of directors, removing unfettered control by Facebook’s CEO Mark Zuckerberg over decisions affecting user privacy.” Firing these members requires a supermajority of the Facebook board of directors.

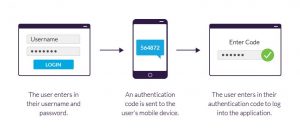
Figure 2: Schematic of Facebook’s Privacy Compliance System
Facebook was also required to designate compliance officers who are responsible for Facebook’s privacy program; these individuals are subject to the approval of the board privacy committee and can be removed only by that committee. The compliance officers and Facebook CEO Mark Zuckerberg must independently submit quarterly certifications to the FTC to show that the company is complying with the mandated privacy program, which applies to Facebook, Instagram, and WhatsApp. Misrepresenting certification status can result in civil and criminal penalties for these individuals.
The other cog in the compliance system is an outside independent third-party assessor, approved by the FTC, who evaluates the effectiveness of Facebook’s privacy program and identifies gaps.
Additionally, Facebook must “conduct a privacy review of every new or modified product, service, or practice before it is implemented, and document its decisions about user privacy”, as well as document any incident where data of 500 or more users has been compromised within 30 days of discovery. Other new requirements stipulated by the FTC include increased oversight of third-party apps, utilizing user phone numbers only for security protocols, express user consent for enabling facial recognition, a comprehensive data security program, and encrypting passwords.
But will all of this be enough to coerce Facebook to respect the privacy of its users and abide by the FTC’s orders? The stakes are huge, not only for consumer privacy, but more broadly for issues as diverse as election integrity and monetary policy. Brittany Kaiser, one of the Cambridge Analytica whistleblowers, said “Facebook is actually the biggest threat to our democracy, not just foreign actors… I say that specifically because it was only two weeks ago that Mark Zuckerberg decided that Facebook is not going to censor politicians that are spreading disinformation, weaponizing racial hatred and even using voter suppression tactics”. During Zuckerberg’s October 23 congressional inquiry regarding Libra cryptocurrency, he was again questioned about Cambridge Analytica. It’s an issue that will not go away.
Ultimately, time will tell whether Facebook has learned its lessons from the recent FTC actions. If it hasn’t, everyone should hope that the FTC vigorously enforces its July order, and reacts even more strongly to prevent future harms.