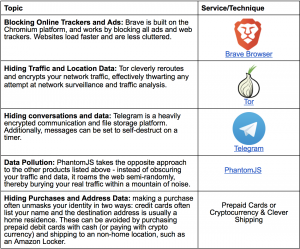
Are Internet and Social Medias Making the Society More Polarized?
By Shirley Deng | July 19, 2019
The Problem
Misinformation and fake news are the problems we today try very hard to combat, as they tend to result in conspiracy theories and plots, ended in hatred and causing the society to be more polarized. It seems like, these problems are only increasing, making larger impacts and more serious consequence due to ease access to the Internet. Rising scandals and strengthening regulations also help to put all these issues to people’s attention.
The Factors
Yet, the society, people and government institutions are also putting the blames to the Internet and more specially, social medias. On October 2018, Peter Bergen and David Sterman addressed on New American that, today, the main terrorist problem in the United States today is one of individuals radicalized by a diverse array of ideologies absorbed from the Internet [1]. Also, as the Stanford professor, Francis Fukuyama points out, polarization might be caused and fostered by many reasons. Though Americans are sorting themselves out geographically, living in increasingly politically homogeneous neighborhoods, social media and the proliferation of media channels via the Internet and TV has played a role allowing people to communicate exclusively with people like themselves [2].
Unquestionably, the development of Internet has enabled connection between people disregard geographic barriers, fostered all kinds of conversations in no time, and given people access to content in their own preference, all thanks to social media and recommendation algorithms. However, in psychology studies, there are also lots of other factors indicating why conspiracy theories spread fast and adopted in scale. Specifically, people who have a low level of analytic thinking, like to overestimate the casual tendency between co-occurring events, or are anxious and feel powerless are more likely to turn to conspiracy theories [3].
A group of researchers from Laboratory of Computational Social Science and other institutions have run an experiment on Facebook to test the difference of spreading patterns on scientific topics and conspiracy (rumors) [4]. The only difference between a science topic and a conspiracy rumor is that whether it is validated with a process. Their experiment and model resulted in very interesting findings that: regardless science topics or conspiracy rumors, when people first receive such information, they tend to share with their close friends first. In other words, most of times, information is taken by a friend who have the same profile (polarization), belonging to the same echo chamber. Users tend to aggregate in communities of interests, causing reinforcement and fostering confirmation bias, segregation and polarization. Interestingly, rumors, as they are aversely against the truth and are more easily to be picked up and thus they have a positive relation between lifetime and size, unlike science topics’ lifetime does not correspond to a higher level of interests.
Yes, Internet and social media sites might have fueled conspiracy rumors, not because Internet and social medias are evil in nature, but because people leverage Internet and social medias to foster their own bubbled communities when people tend to share the conspiracy-related information with other conspiracy believers rather than non-believers [5]. In this way, believes and bias misinformation would be reinforced inside each of these communities, resulting stronger polarized believes.
The Potential Solutions
Before blaming Internet and social medias, it is more meaningful and insightful for us to look into human factors. Lots of psychology studies have given us the hint that people are more interested in exaggerated, distorted information that fits into their theories. People who share them are either firm believers or people who have doubts, unsatisfied with current situations or people who have lower level of analytical thinking abilities.
Social and Education
When social medias might help on building bubbles, bursting the bubble seems to be an obvious way to help avoid people tent to share the same profiles going to extreme. Educations might include helping people to adopt the ideas that people are different, and life is not about debating being right or wrong. Oftentimes, extreme polarized information could be a mix of fact and rumors, which makes the situation more complex. It helps to expose people to different opinions and the corresponding facts and evidences, then we could encourage people to find common grounds.
Fact-Checking
The psychology studies also suggest that when people have doubts, we should give them facts. The rising amount of media outlets focused on fact-checking and political accountability reporting has definitely played an important role on helping with the issue.
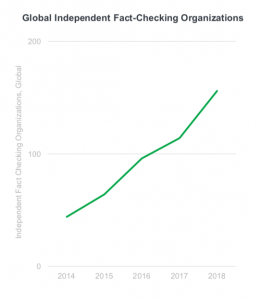
Source: Mary Meeker’s Internet Trend Report [6]
The increasing amount of controversy on the credibility of journalist has made fact-tracking more important, as Alan Greenblatt puts, “This is an incredibly important time to be a journalist. Never has the watchdog role been more important.” [7] During the presidential campaign in 2016, at least 6 million people had flocked to a transcript of the debate that was fact-checked by 20 NPR journalists in real-time [8]. Globally, partnerships between social medias, Internet companies and science institutions also help to build a safer and healthier online environment.
Technology and Product
While Internet companies and social medias should not take all the blames, they could take up some responsivities to act proactively and maintain safer and healthier online communities. For example, algorithmic-driven solutions have been proposed and Google is developing a trustworthiness score to rank the results of queries to estimate the trustworthiness of a web source and build knowledge-based trust. WeChat, the social media giant in China, builds an in- app official fact-checking channel that helps to label rumors and stop them from spreading. WhatsApp, the messaging app who hosts a quarter of global populations on it, labels all forwarded messages and reminds its user to think twice before forwarding to others.
Legal
Last but not the least, legal should be an important resort to fight the bad actors in our communities, regardless online or offline. Lots of conspiracy theories that aims to driving people to polarized directions could be initiated by people with ulterior motives. In this regard, besides guidelines and policies, we should hold the bad actors accountable for their own actions. For example, in 2013, in order to combat rumors, the Chinese government brought out tough measures to stop the spread irresponsible rumors, threatening three years in jail if untrue posts online are widely reposted [10]. Although it drew lots of angry responds from the internet users in China initially, it did help to contain the spread of rumors and minimize bad impacts.
Citations:
[1] “The Real Terrorist Threat in America”, https://www.newamerica.org/international-security/articles/real-terrorist-threat-america/
[2] “The Great Recession has influenced populist movements today, say Stanford scholars”, https://news.stanford.edu/2018/12/26/explaining-surge-populist-politics-movements-today/
[3] “The Psychology of Conspiracy Theories” aps Association for Psychological Science, https://journals.sagepub.com/doi/pdf/10.1177/0963721417718261
[4] “The spreading of misinformation online”, PNAS January 19, 2016 113 (3) 554-559; first published January 4, 2016 https://doi.org/10.1073/pnas.1517441113
[5] “The internet fuels conspiracy theories – but not in the way you might imagine”, http://theconversation.com/the-internet-fuels-conspiracy-theories-but-not-in-the-way-you-might-imagine-98037
[6] “Internet Trend Report”, 2019, Mary Meeker
[7] “The Future of Fact-Checking: Moving ahead in political accountability journalism”, https://www.americanpressinstitute.org/publications/reports/white-papers/future-of-fact-checking/
[8] “NPR’s real-time fact-checking drew millions of readers”, https://www.poynter.org/fact-checking/2016/nprs-real-time-fact-checking-drew-millions-of-viewers/
[9] “Knowledge-Based Trust: Estimating the Trustworthiness of Web Sources”, http://www.vldb.org/pvldb/vol8/p938-dong.pdf
[10] “China threatens tough punishment for online rumor spreading”, https://www.reuters.com/article/us-china-internet/china-threatens-tough-punishment-for-online-rumor-spreading-idUSBRE9880CQ20130909?feedType=RSS&feedName=technologyNews