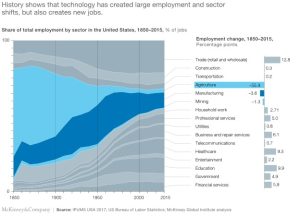
Beauty is in the eye of the algorithm?
Anonymous | October 20, 2022
AI generated artwork has been making headlines over the past few years, but many artists wonder if these images can even be considered art.
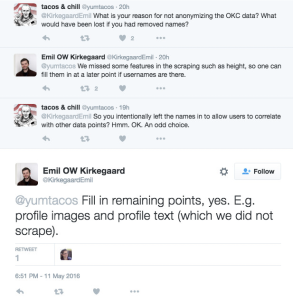
Can art be created by a computer? Graphic design and digital art have been around for decades, and these techniques require experience, skill and often years of education to master. Artists have used tools such as Adobe Photoshop to traverse this medium and produce beautiful and intricate works of art. However, in the last few years new types of artificial intelligence software, such as DALL-E 2, have enabled anyone, even those without experience or artistic inclination, to produce elaborate images by entering just a few key words. This is exactly what Jason Allen did to win the Colorado State Fair art competition in September 2022: he used the AI software Midjourney to generate his blue ribbon winning piece “Théâtre D’opéra Spatial”. Allen did not create the software, but had been fascinated by its ability to create captivating images and wanted to share it with the world. Many artists were outraged by the outcome, but Allen maintains that he did nothing wrong as he did not break any of the rules of the competition nor did he try to pass of the work as his own, submitting it under “Jason Allen via Midjourney”. The competition judges also maintained that though they did not initially know that Midjourney was an AI program, they would have awarded Allen the top prize regardless. However, it seems that the ethical impacts here go deeper than the rules of the competition themselves.

“Théâtre D’opéra Spatial” via Jason Allen from the New York Times
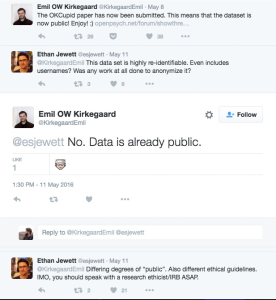
A few questions come to mind when analyzing this topic. Can the output of a machine learning algorithm be considered art? Is the artist here the person who entered the phrase into the software, the software itself, or the developer of the software? Many artists argue that AI cannot produce art because its outputs are devoid of any meaning or intention. They say that art requires emotion and vulnerability in order to be truly creative, though it seems incorrect to try and define the term “art”. Additionally, critics of AI softwares claim that they are a means of plagiarism as the person inputting the key words did not create the work themselves and the software requires previous work as a basis for its learning, so the output is necessarily based on other people’s effort. This is not, however, the first time that AI generated art has made headlines. In 2018, an AI artwork sold for $432,500 after being auctioned at Christie’s. The work, Portrait of Edmond Belamy, was created by Obvious, a group of Paris based artists, who programmed what they coined a “generative adversarial network”. This system consists of two parts, a “generator” and a “discriminator”, the first which creates the image and the second which tries to differentiate between human created and machine generated works. Their goal was to fool the “discriminator”. The situation here was slightly different from the Midjourney generated art as the artists were also the developers of the algorithm and the algorithm itself seems to be credited.

Portrait of Edmond Belamy from Christie’s
As someone who has no artistic ability or vested interest in the world of art, it was difficult to even form an opinion on some of these ethical questions, but the complexity of this topic intrigued me. However, even though this is not a research experiment, the principles of The Belmont Report are relevant in this situation. First, there seems to be an issue with Beneficence here. Beneficence has to do with “maximizing possible benefits and minimizing possible harms.” Allowing or entering AI generated art in a competition is in conflict with this principle. Artists often spend countless hours perfecting their works whereas software can create it in a matter of seconds, so there is a lot of potential for harm here. The winner of the Colorado state fair competition in particular also received a $300 prize, which is money that could have gone to an artist who had a more direct impact on their submission. Furthermore, there is the issue of Justice also mentioned in the Belmont Report. Justice has to do with people fairly receiving benefits based on the effort they have contributed to some project. As mentioned above, the works generated by AI will be based on other people’s intellectual property, but those people will not receive any credit. Additionally, in both the Christie’s and Colorado State Fair cases, the artists are profiting from these works, so there is a case to be made that those whose art was used to train the algorithms are also entitled to some compensation. In the end, it seems that this is another case of technology moving faster than the governing bodies of particular industries. Moving forward the art world must decide how these newer and more advanced softwares fit into spaces where technology has historically, and often intentionally, been excluded.
References:
https://www.nytimes.com/2022/09/02/technology/ai-artificial-intelligence-artists.html
https://www.hhs.gov/ohrp/sites/default/files/the-belmont-report-508c_FINAL.pdf