Is the New Internet Prone to Old School Hacks?
By Sean Lo | October 20, 2022
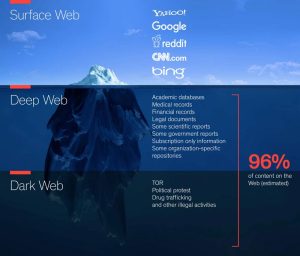
The blockchain is commonly heralded as the future of the internet, however, Opensea’s email phishing incident in June 2022 proved that we may still be far away from true online safety. We are currently in the midst of one of the biggest technological shifts in the past few decades. What many people are referring to as Web3.0; blockchain is the main technology that is helping build the future of the internet. Underneath this shift, is the idea that the new age internet will be decentralized. In other words, the internet should be owned by the collective group of people that actually uses it, v.s what we have today.
In June 2022, Opensea, one of the largest Non-fungible token (NFT) marketplaces got hacked and lost 17 of their customers their entire NFT collection. It was reported that the value of the combined stolen assets was north of $2 million dollars. The question is then, how is it possible that the blockchain got hacked? Wasn’t the security of the blockchain the main feature that is promised in the new age internet? These are 2 very valid questions as a flaw in the blockchain would ultimately highlight the potential flaws of using the blockchain entirely. What was interesting about this specific incident was that the hack was actually a simple phishing scam, a type of scam that existed since the beginning of email. Opensea reported that an employee at customer.io, the email automation and lifecycle marketing platform Opensea uses, downloaded their email database to send a phishing email. In the attached image below reads the email that was sent to all Opensea customers. This was a couple months after the long awaited Ethereum merge, and the email used this opportunity to trick some users into signing malicious contract.

Opensea phishing email
As mentioned before, social engineering and phishing hacks have always been part of the internet. In fact, the “Nigerian prince” email scam still ranks in roughly $700K a year in lost funds. What makes this specific phishing incident so interesting is because it was done through a Web3.0 native company, and the stolen funds were all stolen directly on the blockchain. By pretending to be Opensea, they were able to get customers to sign a smart contract which the contract proceeded to drain the signers digital wallet. For context, smart contracts are a set of instructions that are binded by the blockchain, think of it as a set of instructions for the computer program to run. Smart contracts are written in the coding language called Solidity, so unless you can read that language, its highly likely that you aren’t aware of what you are signing.
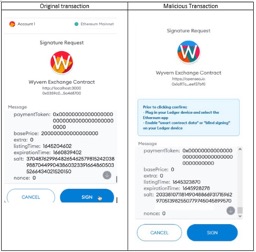
Fake smart contract message
As we venture into the world of Web3.0 where blockchain is the underlying technology that is central to many types of online transactions, there comes a question of how liability and security should be governed in this new world. We’re still very early in the innings around Web3.0 adoption, and I truly believe we’re still likely half a decade away from true mass adoption. On top of all the existing Web2.0 regulations that companies need to follow, the government must also step up to create new laws to keep the regular citizen from malicious online acts. The anonymity of the blockchain does pose potential risks to the entire ecosystem, which is why I believe there must be federal laws around the technology to push us towards mass adoption. It’s really a matter of when rather than if, as there is a pretty clear increase in uses across the entire tech industry.