How to Avoid Information Bias During the Mid-terms Rush Ashford | October 14, 2022
Not all social media platforms promote and police political information equally. Understand the steps you can take as a user of these platforms to limit your political information bias.
Social media platforms played a significant role in the outcome of recent elections1. Over 90%2 of Americans actively use social media platforms, making them an increasingly relied-upon outlet for politicians, activists, and companies to campaign, distribute information and engage with voters. Social media platforms are not bound by law to ensure that information is correct or that all political parties are given equal visibility to users. In fact, the business model of most social media platforms benefits from attention-grabbing or polarizing content that gets more likes and shares.
With a lack of regulation, is it easy for users of these platforms to be exposed to misinformation or only be shown a one-sided view of the world. With the US mid-term elections fast approaching, this article outlines steps that you can take to avoid information bias when it comes to political content on social media platforms.
Placards with images of social media platform icons Source: TechnologySalon
What is information bias?
In research, the term ‘information bias’ is used when a study has excluded or augmented data to show a version of events that is different from the truth.
When using social media platforms, you have probably noticed that you aren’t only shown content generated by your friends. Is it no secret that platforms like Facebook, Snapchat, and LinkedIn use your data to expose you to paid adverts and recommend content or accounts they think you will engage with. When it comes to political content, this is problematic for several reasons:
Misinformation – most of the content on these platforms does not come from a reputable news source.
Influence – by being repeatedly shown the same opinion without displaying alternate viewpoints, you may develop this as your own belief.
Sponsorship – as with any advertisements, it’s essential to understand who has paid for this content and their motivation.
How do social media platforms govern political information?
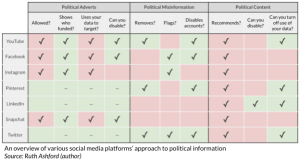
Each platform handles content containing political information differently, as there aren’t many laws dictating what should be done. A platform’s stance on how they surface political content, political adverts and deal with misinformation largely determines the information you are exposed to. By giving an overview of the approach that the major platforms4 take, I hope you better understand how to use them to limit your political information bias.
Political Adverts
Social media platforms are polarized when accepting payment for adverts containing political content. Pinterest, LinkedIn, and Twitter have all banned political adverts, with Twitter stating that “political message reach should be earned, not bought”3. YouTube, Facebook, Instagram, and Snapchat show political adverts, but all of them, apart from Instagram, allow you to turn down the number of political adverts you see. You can do this by going into your Ad Settings.
Political Misinformation
Fake news can spread like wildfire on social media platforms, creating an image of a party or candidate that is hard to shake. Social media platforms have put varying degrees of effort into identifying misinformation, most using algorithms, and independent fact-checkers. They have different approaches to what they do when they find it; Twitter, Pinterest, and YouTube will actively remove political misinformation and disable accounts that continually post it. Facebook and Instagram do not remove political misinformation, but they will flag it as potentially misleading. LinkedIn and Snapchat do not mention any recourse for spreading misinformation in their Community Policies, meaning extra vigilance is needed when consuming their content.
Political Content
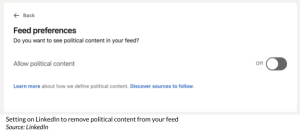
Outside of paid advertisements, your social media newsfeed will contain content that is recommended for you. These recommendations are driven by your personal information, your activity both on and off the social media platform, and what your friends are engaging with. By showing you similar content to what you have previously engaged with or what your network engages with, you are likely shown a one-sided view of the world regarding recommended political content. To help diversify what you see, YouTube, LinkedIn, Pinterest, and Twitter let you turn off certain parts of your data used for recommendations, which is done through your Privacy Settings. LinkedIn goes one step further and allows you to remove recommended political content from your feed altogether.
Social media can surface a wealth of political information and be a fantastic space to debate and discuss critical topics. As users of these platforms, we must be aware of the type of information shown, who’s funding it, and how accurate it is to ensure we form political opinions grounded in truth.
Public Advocacy Blog Post Jordan Thomas | October 8, 2022
Let’s take some of the engineering out of AI
AI recommendation systems are built by engineers but engineers shouldn’t be totally in charge of them. We need non-machine learning experts working on these systems too. Including regular people on AI teams will reduce bias and improve the performance of the systems.
There is no escaping recommendations. AI is used to recommend things to us in products all the time. Obvious examples are amazon recommending products to buy or Netflix recommending movies to watch. Once you know what to look for you’ll find recommendation systems everywhere you look. And despite being used everywhere, the recommendations of these systems are often poor in quality.
Computer programs using machine learning techniques are what power most recommendation systems and, at their heart, the systems are methods of transforming data about what happened in the past into predictions about what will happen in the future. Those systems are technical feats of engineering taking months or years to build. And because they require expertise in a combination of computer science and statistics, these systems are usually built by a team of engineers with a math and statistics background.
Somewhat surprisingly, the personal characters of those who build these systems have profound impacts on the recommendations provided. This is not a new insight. Much has been written on the topic of how algorithms can encode the biases of people who build them and society at large. Research papers like this one by Inioluwa Deborah Raji (https://arxiv.org/abs/2102.00813) and news articles like “Who Is Making Sure the A.I. Machines Aren’t Racist?” (https://www.nytimes.com/2021/03/15/technology/artificial-intelligence-google-bias.html) are both excellent explorations of these arguments. But there is another reason we should be concerned with who is chosen to build these systems: if non-machine learning experts are part of the teams building the systems the recommendations could be a lot better. The reason for this has to do with what machine learning practitioners refer to as “Feature Engineering”.
Feature engineering is a critical step in the development of most recommendation systems. It is a process where humans, typically data scientists and engineers, define how to process “raw data” into the “features” the system will learn from. Many people have the mistaken impression that recommendation systems consume raw data in order to learn how to make accurate recommendations. The reality is that, in order to get these systems to deliver anything better than random guesses, engineers have found that features must be defined manually. Those features are the kinds of things that we as humans understand to be important to making a prediction. So, for example, if we are building a system to recommend products we might define features related to how often users buy big-ticket items, the categories of items they have bought in the past, their hobbies, and so on. Those features are requirements for good performance because algorithms do not know on their own that hobbies tell us something about what a human is likely to buy. This process of transforming raw data into features that have information that is important is called feature engineering.
And that’s why including non-experts on the teams building these AI systems is so important. Data scientists and engineers are experts in building programs but they are not usually also experts in why people buy products, watch movies, cheat on taxes, or any other of the millions of applications for recommendation systems. I have personally seen this dynamic play out countless times. I am a sys-gender white male from an upper-middle-class background in California. To date, all of the engineering teams I have worked with that built recommendation systems were staffed with people of the same background.
Including people unfamiliar with machine learning, but with knowledge about the domain can dramatically improve the quality of the features engineered which in turn gives algorithms better data to work with and results in better recommendations overall. Including people who have experience with the problem firsthand also means considering the positionality of the team members. Because recommendation systems are frequently used by everyone, it is essential that the team that builds them be representative of a diverse set of experiences. If instead those teams continue to be composed of people from privileged backgrounds, not only will the job opportunities be unequal, but the recommendations we all receive will be worse than they need to be.
In the past, the “bright” in bright future is a metaphorical term, meaning the limitless possibilities we have ahead of us; nowadays, the “bright” is ironically stating the brightness of the screens on our smart devices, which could be our phones, tablets, and any interface that connects us to the Internet. How many times have we bear witness to odd families dining scene at restaurants, when the family members are preoccupied with their smart devices, as opposed to having normal conversations with one another? How many times have we seen adults gave their phones to their kids, just so the children will be quiet and leave the adults in peace? On a more worrisome note, how many of us was aware that our interaction with the digital world was transformed into data, and such info was being collected covertly and used against us?
How are we being controlled by the online world?
We are so addicted to our phones and the Internet that we hardly pay attention to what is happening around us. We lost the ability to think independently. While we “voluntarily” hooked ourselves on the Internet, our regulations on internet privacy, personal data protection, and cyber security were very much lagged behind. Recently, we saw Facebook’s, now Meta, CEO Mark Zuckerberg testified in front of the Congress in regards to the newsfeeds during the 2016 presidential election. However, members of the Congress at the time did not do their due diligence as to understand how the algorithms and the mechanics of the Internet works. While the Internet evolves ever so rapidly, our legal frameworks struggle to keep up [1].
From the book Stolen Focus by Johann Hari, “false claims spread on social media far faster than the truth, because of the algorithms that spread outraging material faster and farther. A study by the Massachusetts Institute of Technology found that fake news travels six times faster on Twitter than real news, and during the 2016 U.S. presidential election, flat-out falsehoods on Facebook outperformed all the top stories at nineteen mainstream news sites put together. As a result, we are being pushed all the time to pay attention to nonsense—things that just aren’t so.” [2].
It is not news that big tech companies have algorithm that they use to “trap” you to stay on their platform. They have written codes that automatically decide what we will see [1]. Due to the algorithms, we see that algorithmic spread out hate speeches, disinformation, and conspiracy theories via major Internet platforms, and those had undermined America’s response to the COVID-19 pandemic. It has also increased political polarization and helped promote? white supremacy organizations. [3]
There are all sorts of algorithms they the big tech companies could use, ways they could decide what you should see, and the order in which you should see them. The algorithm they use varies all the time, but it all has one key driving principle – consistency. It shows you things that will keep you focused on your screen. That is the more time you stay on, the more money they generate. Therefore, the algorithm is designed to occupy your attention to the fullest whenever possible. It is designed to distract you from what matters most [2].
How behind are we in regulations for online privacy?
Public demands for policy maker for change began nearly a decade ago, when the Federal Trade Commission entered into a consent decree with Facebook, it was designed to prevent the Platform from sharing user data with third parties without prior consent [3]. However, nothing have improved since.
When we look at the history of regulatory and policy act, there are not many out there to regulate the use of data that are being collected from us, the users. As big tech giants, now armed with worldwide impact it is not helping the policy makers to create regulations in regards to the four major area – safety, privacy, competition, and honesty.
We are still relying on the US Privacy Act of 1974 to help guard and lay the foundation of laws covering data and internet privacy in the US. Later on comes the Federal Trade Commission (FTC) Act which provides guidelines on outlawing (or use “ruling out” instead?) unfair methods of competition and unfair acts or practices that affect commerce. We have Children’s Online Privacy Protection Act (COPPA) in 1998 to protect children. And the most recent, California Consumer Privacy Act (CCPA), which was signed into law in 2018, addressing consumer privacy by extending it to protections to the Internet. Similar to EU’s General Data Protection Regulation (GDPR), it give consumers the right to access their data, along with the right to delete and opt out of data processing at any time. However, CCPA differs from GDPR in the sense that GDPR grants consumers a right to correct or rectify incorrect personal data, whereas CCPA doesn’t. GDPR also requires explicit consent at the point when consumers hand over their data [1].
Moving forward
Although there are limited legal protections to internet interactions, bringing forward the awareness on ethical issues and privacy concerns is a good start. By understanding the privacy policy and the current regulation, it will help us act in movements towards better policies and regulations to protect our data. We may participate in the antitrust suit to help shape the future of the digital word. The more awareness and participation from the end users, the easier it will be for the policy makers to move forward with better regulations.
Citation
1. Kaspersky. (2022, May 11). What are some of the laws regarding internet and data security? www.kaspersky.com. Retrieved October 4, 2022, from https://www.kaspersky.com/resource-center/preemptive-safety/internet-laws
2. Hari, J. (2022, January 25). Stolen Focus: Why You Can’t Pay Attention–and How to Think Deeply Again. Crown.
3. McNamee, R. (2020, July 29). Big Tech Needs to Be Regulated. Here Are 4 Ways to Curb Disinformation and Protect Our Privacy. Time. Retrieved October 4, 2022, from https://time.com/5872868/big-tech-regulated-here-is-4-ways/
4. Wichowski, A. (2020, October 29). Perspective | the U.S. can’t regulate big tech companies when they act like nations. The Washington Post. Retrieved October 4, 2022, from https://www.washingtonpost.com/outlook/2020/10/29/antitrust-big-tech-net-states/
5. Chang, J. (2022, January 14). 90 smartphone addiction statistics you must see: 2022 usage and data analysis. Financesonline.com. Retrieved October 5, 2022, from https://financesonline.com/smartphone-addiction-statistics/
6. Paris, J. (n.d.). Struggling with Phone Addiction? Try This. Retrieved October 5, 2022, from https://thriveglobal.com/stories/struggling-with-phone-addiction-try-this/
Finding Red Flags in Privacy Policies Ben Ohno | October 6, 2022
Companies tell us in their privacy policies what they do and do not do with our data… or do they?
Privacy has been a consistent subject in the news over the past few years due to data breaches like Cambridge Analytica and Equifax in 2017. As a result, privacy policies are becoming more scrutinized because these privacy policies communicate what kinds of protections users have on their platform. Most users do not read the privacy policy, but there are certain things that a user could look for in a very brief skim of the privacy policy. While there’s no national laws that govern privacy policies in the US, there are certain pieces of information that privacy policies should have. In this blog post, I will highlight some aspects of the privacy policy a user can review manually and some automated capabilities that attempt to do this for the user.
Within the privacy policy:
Privacy policies should have contact information available for users to reach out to. Preferably this will be some kind of contact within the legal counsel side of things. Without this contact information, users would have no avenue to understand their protections of the privacy policy. In addition, if there’s third party access to the data, users should know who these third parties are. In Solove’s Taxonomy, there’s a section around information processing and secondary use of data. In Solove’s Taxonomy, secondary use of data is a privacy risk to users. When companies give data to third party vendors, the third party vendors often do not have to follow the same policies and practices as the company who gave them the data. Lastly, privacy policies with overwhelming vocabulary, jargon and an ambiguous tone can be problematic. Companies with policies that are difficult to understand may be hiding exactly what they are doing with the data.
Outside the privacy policy:
There are certain flags to look for that do not have to do with the content of the privacy policy. Based on this article from Forbes, the privacy policy should be easy to find. If it is not easily findable, the company may be a sign that the company is not transparent about how it handles user data. Another thing to consider is if the company follows their own privacy policy. If there have been privacy breaches for this company in the past, that is a clear sign that they have not followed their privacy policy in the past. Lastly, companies should post when their privacy policy was last updated. A red flag would be if it has been many years since the last update or if a company has not updated the privacy policy after a data breach.
Automated capabilities:
Terms of Service, Didn’t Read (TOSDR), is a site that aims to summarize privacy policies and highlight red flags for users. However, it does not have the ability to read any privacy policy. It has a finite database of larger companies’ privacy policies. Useableprivacy.org is a site that analyzes privacy policies with crowdsourcing, natural language processing, and machine learning. It is a blend of human and machine learning analysis of privacy policies. The site provides a report for each company it has in its database. Outside of sites that summarize privacy policies and flag potential privacy concerns, we can also use natural language processing to determine the reading complexity of a privacy policy. Commonsense.org discusses metrics such as the Automated Reading Index and Coleman-Liau Index as measures for how complex a document is to read.
Looking forward:
Hopefully this blog post was helpful for readers to understand a bit more about privacy policies and what flags and tools to look out for to help people understand privacy policies. The state of privacy now is evolving and the privacy space changes quickly. In the future, I hope that there are federal laws that mandate a standardized easy way to communicate privacy policy content to the user in a concise and manageable way.
Protecting your privacy through disposable personal information Anonymous | October 8, 2022
Protecting your privacy through disposable personal information The next time you sign up for a coupon code or make an online purchase, take these simple steps to protect yourself from fraud.
Paying for goods and services online is a common way that many of us conduct business nowadays. In addition to paying for these goods and services, whatever platform we chose to use on the web typically requires us to sign up for new accounts. This leaves the privacy of our sensitive personal information such as credit card details, name, email address at the mercy of the organizations or platforms we conduct business on. Using disposable personal information might be an easy way to safeguard our information in the event of a data breach.
What is disposable personal information?
Disposable or virtual card numbers are like physical credit cards but they only exist in a virtual form. A virtual credit card is a random 16-digit number associated with an already-existing credit card account. A virtual card becomes available for use immediately after being generated and is usually only valid for 10 minutes after. The original credit card number remains hidden from the merchant. This offers customers security by protecting information directly linked to bank accounts and can help limit how much information is accessible to fraudsters if a customer’s information is stolen in a phishing scam or a data breach.
Disposable email on the other hand, is a service that allows a registered user to receive emails at a temporary address that expires after a certain time period. A disposable email account has its own inbox, reply and forward functions. You should still be able to log into the app or service you’ve signed up for, but once the email address expires, you won’t be able to reset your password, delete your account, or do anything else using that email. Depending on the service, you might be able to change your disposable email address for a real one.
How do you create your own disposable information?
The easiest way to create your own virtual credit card is to request one through your credit card issuer. Many banks such as Capital One and Citi Bank offer virtual cards as a feature. Check with your financial institution if they have this service. Another option is to save your personal financial information, along with address on Google Chrome and allow the browser to automatically populate this information when you have to pay online. Google encrypts this information so that the merchant has no visibility to your sensitive information. Lastly, you can use an app like Privacy to generate virtual card numbers for online purchases. With this app, you can also create virtual cards for specific merchants and set spending limits on those cards, along with time limits on when they expire.
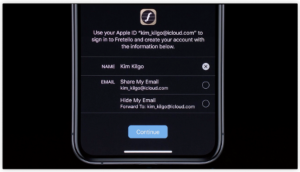
Creating disposable email addresses for web logins is straightforward if you have an Apple device. The option to use disposable email addresses is already an included feature. If the app or website you are using offers a Sign In With Apple option, you can register with your Apple ID, and select Hide My Email in the sharing option. By selecting this option, Apple generates a disposable email address for you, which relays messages to your main address.
You can also use services such as Guerilla Mail or 10-Minute Mail to generate a disposable email address.
An Artificial Intelligence (AI) Model Can Predict When You Will Die: Presenting a Case Study of Emerging Threats to Privacy and Ethics in the Healthcare Landscape Mili Gera | October 7, 2022
AI and big data are now part of sensitive-healthcare processes such as the initiation of end-of-life discussions. This raises novel data privacy and ethical concerns; the time is now to update or eliminate thoughts, designs, and processes which are most vulnerable.
An image showing the possibility of AI tools to identify patients using anonymized medical records. Figure by Dan Utter and SITN Boston via https://sitn.hms.harvard.edu/flash/2019/health-data-privacy/
Data Privacy and Ethical Concerns in the Digital Health Age
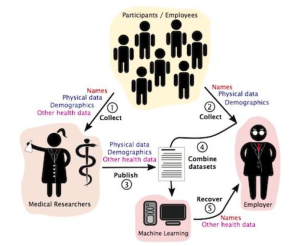
With the recent announcements of tech giants like Amazon and Google to merge or partner with healthcare organizations, legitimate concerns have arisen on what this may mean for data privacy and equity in the healthcare space [1,2]. In July 2022, Amazon announced that it had entered into a merger agreement with One Medical: a primary care organization with over a hundred virtual and in-person care locations spread throughout the country. In addition, just this week, Google announced its third provider-partnership with Desert Oasis Healthcare: a primary and specialty provider network serving patients in multiple California counties. Desert Oasis Healthcare is all set to pilot Care Studio, an AI-based healthcare data aggregator and search tool which Google built in partnership with one of the largest private healthcare systems in the US, Ascension [2]. Amazon, Google, and their care partners all profess the potential “game-changing” advances these partnerships will bring into the healthcare landscape, such as greater accessibility and efficiency. Industry pundits, however, are nervous about the risk to privacy and equity which will result from what they believe will be an unchecked mechanism of data-sharing and advanced technology use. In fact, several Senators, including Senator Amy Klobuchar (D-Minn.) have urged the Federal Trade Commission (FTC) to investigate Amazon’s $3.9 billion merger with One Medical [1]. In a letter to the FTC, Klobuchar has expressed concerns over the “sensitive data it would allow the company to accumulate” [1].
While Paul Muret, vice president and general manager of Care Studio at Google, stated that patient data shared with Google Health will only be used to provide services within Care Studio, Google does have a patient data-sharing past which it got in trouble for in 2019 [2]. The Amazon spokesperson on their matter was perhaps a bit more forthcoming when they stated that Amazon will not be sharing One Medical health information “without clear consent from the customer” [1]. With AI and big data technologies moving so swiftly into the most vulnerable part of our lives, it’s most likely that nobody, not even the biggest technology vendor who may implement algorithms or use big-data, understands what this may mean for privacy and equity. However, it is important that we start to build the muscle memory needed to tackle the new demands on privacy protection and healthcare ethics which the merger of technologies, data and healthcare will bring into our lives. To this end, we will look at one healthcare organization which has already implemented big data and advanced machine learning algorithms (simply put, the equations which generate the “intelligence” in Artificial Intelligence) in the care of their patients. We will examine the appropriateness behind the collection and aggregation of data as well as the usage of advanced technologies in their implementation. Where possible, we will try to map their processes to respected privacy and ethics frameworks to identify pitfalls. Since the purpose of this study is to spot potentially harmful instantiations of design, thoughts or processes, the discourse will lean towards exploring areas ripe for optimizations versus analyzing safeguards which already do exist. This is important to remember as this case study is a way to arm ourselves with new insights versus a way to admonish one particular organization for innovating first. The hope is that we will spark conversations around the need to evolve existing laws and guidelines that will preserve privacy and ethics in the world of AI and big data.
Health Data Privacy at the Hospital
In 2020, Stanford Hospital in Palo Alto, CA launched a pilot program often referred to as the Advanced Care Planning (ACP) model [3]. The technology behind the model is a Deep Learning algorithm trained on pediatric and adult patient data acquired between 1995 and 2014 from Stanford Hospital or Lucile Packard Children’s hospital. The purpose of the model is to improve the quality of end-of-life (also known as palliative) care by providing timely forecasters which can predict an individual’s death within a 3-12 month span from a given admission date. Starting with the launch of the pilot in 2020, the trained model automatically began to run on the data of all newly-admitted patients. To predict the mortality of a new admission, the model is fed twelve-months worth of the patient’s health data such as prescriptions, procedures, existing conditions, etc. As the original research paper on this technology states, the model has the potential to fill a care gap, since only half of “hospital admissions that need palliative care actually receive it” [4].
However, the implementation of the model is rife with data privacy concerns. To understand this a little better we can lean on the privacy taxonomy framework provided by Daniel J. Solove, a well-regarded privacy & law expert. Solove provides a way to spot potential privacy violations by reviewing four categories of activities which can cause the said harm: collection of data, processing of data, dissemination of data and what Solove refers to as invasion [5]. Solove states that the act of processing data for secondary use (in this case, using patient records to predict death versus providing care) violates privacy. He states, “secondary use generates fear and uncertainty over how one’s information will be used in the future, creating a sense of powerlessness and vulnerability” [5]. In addition, he argues it creates a “dignitary harm as it involves using information in ways to which a person does not consent and might not find desirable” [5].
A reasonable argument can be made here that palliative care is healthcare and therefore cannot be bucketed as a secondary use of one’s healthcare data. In addition, it can be argued that prognostic tools in palliative care already exist. However, this is exactly why discussions around privacy and specifically privacy and healthcare need a nuanced and detailed approach. Most if not all palliative predictors are used on patients who are already quite serious (often in the I.C.U). To illustrate why this is relevant, we can turn to the contextual integrity framework provided by Helen Nissenbaum, a professor and privacy expert at Cornell Tech. Nissenbaum argues that each sphere of an individual’s life comes with deeply entrenched expectations of information flows (or contextual norms) [6]. For example, an individual may be expecting and be okay with the informational norm of tra.c cameras capturing their image, but the opposite would be true for a public bathroom. She goes on to state that abandoning contextual integrity norms is akin to denying individuals the right to control their data, and logically then equal to violating their privacy. Mapping Nissenbaum’s explanation to our example, we can see that running Stanford’s ACP algorithm on let’s say for example, a mostly healthy pregnant patient, breaks information norms and therefore qualifies as a contextual integrity/secondary use problem. An additional point of note here is the importance of consent and autonomy in both Solove and Nissenbaum’s arguments. Ideas such as consent and autonomy are prominent components, and sometimes even definitions of privacy and may even provide mechanisms to avoid privacy violations.
In order for the prediction algorithm to work, patient data such as demographic details regarding age, race, gender and clinical descriptors such as prescriptions, past procedures etc., are combined to calculate the probability of patient death. Thousands of attributes about the patient can be aggregated in order to determine the likelihood of death ( in the train data set an average of 74 attributes were present per patient) [4]. Once the ACP model is run on a patient’s record, physicians get the opportunity to initiate advance care planning with the patients most at risk for dying within a year. Although it may seem harmless to combine and use data where the patient has already consented to its collection, Solove warns that data aggregation can have the effect of revealing new information in a way which leads to privacy harm [5]. One might argue that in the case of physicians, it is in fact their core responsibility to combine facts to reveal clinical truths. However, Solove argues, “aggregation’s power and scope are different in the Information Age” [5]. Combining data in such a way breaks expectations, and exposes data that an individual could not have anticipated would be known and may not want to be known. Certainly when it comes to the subject of dying, some cultures even believe that the “disclosure may eliminate hope” [7]. A thoughtful reflection of data and technology processes might help avoid such transgressions on autonomy.
Revisiting Ethical Concerns
For the Stanford model, the use of archived patient records for training the ACP algorithm was approved by what is known as an Institutional Review Board (IRB). The IRB is a committee responsible for the ethical research of human subjects and has the power to approve or reject studies in accordance with federal regulations. In addition, IRBs rely on the use of principles found in a set of guidelines called the Belmont Report to ensure that human subjects are treated ethically.
While the IRB most certainly reviewed the use of the training data, some of the most concerning facets of the Stanford process are on the flip side: that is, the patients on whom the model is used. The death prediction model is used on every admitted patient and without their prior consent. There are in fact strict rules that govern consent, privacy and use when it comes to healthcare data. The most prominent of these being the federal law known as The Health Insurance Portability and Accountability Act (HIPAA). HIPAA has many protections for consent, identifiable data and even standards such as minimum necessary use which prohibits exposure without a particular purpose. However, it also has exclusions for certain activities, such as research. It is most probable therefore that the Stanford process is well within the law. However, as other experts have pointed out, HIPAA “was enacted more than two decades ago, it did not account for the prominence of health apps, data held by non-HIPAA-covered entities, and other unique patient privacy issues that are now sparking concerns among providers and patients” [8]. In addition, industry experts have “called on regulators to update HIPAA to reflect modern-day issues” [8]. That being said, it might be a worthwhile exercise to assess how the process of running the ACP model on all admitted patients at Stanford hospital stacks up to the original ethical guidelines outlined in the Belmont Report. One detail to note is that the Belmont Report was created as a way to protect research subjects. However, as the creators of the model themselves have pointed out, the ACP process went live just after a validation study and before any double blind randomized controlled trials (the gold standard in medicine). Perhaps then, one can consider the Stanford process to be on the “research spectrum”.
One of the three criteria in the Belmont Report for the ethical treatment of human subjects is “respect for persons”: or the call for the treatment of individuals as autonomous agents [9]. In the realm of research this means that individuals are provided an opportunity for voluntary and informed consent. Doing otherwise is to call to question the decisional authority of any individual. In the ACP implementation at Stanford, there is a direct threat to self-governance as there is neither information nor consent. Instead an erroneous blanket assumption is made about patients’ needs around advance care planning and then served up as a proxy for consent. This flawed thinking is illustrated in a palliative care guideline which states that “many ethnic groups prefer not to be directly informed of a life-threatening diagnosis” [7].
An image from the CDC showing data practices as fundamental to the structure of health equity. https://www.cdc.gov/minorityhealth/publications/health_equity/index.html
Furthermore, in the Belmont Report, the ethic of “justice” requires equal distribution of benefits and burden to all research subjects [9]. The principle calls on the “the researcher [to verify] that the potential subject pool is appropriate for the research” [10]. Another worry with the implementation of the ACP model is that it was trained on data from a very specific patient population. The concern here is what kind of variances the model may not be prepared for and what kind of harm that can cause.
Looking Forward
Experts agree that the rapid growth of AI technologies along with private company ownership and implementation of AI tools will mean greater access to patient information. These facts alone will continue to raise ethical questions and data privacy concerns. As the AI clouds loom over the healthcare landscape, we must stop and reassess whether current designs, processes and even standards still protect the core tenets of privacy and equity. As Harvard Law Professor Glen Cohen puts it, when it comes to the use of AI in clinical decision-making, “even doctors are operating under the assumption that you do not disclose, and that’s not really something that has been defended or really thought about” [11]. We must prioritize the protection of privacy fundamentals such as consent, autonomy and dignity while retaining ethical integrity such as the equitable distribution of benefit and harm. As far as ethics and equity are concerned, Cohen goes on to state the importance of them being part of the design process as opposed to “being given an algorithm that’s already designed, ready to be implemented and say, okay, so should we do it, guys” [12]?
Is Ethical AI a possibility in the Future of War? Anonymous | October 8, 2022
Is Ethical AI a possibility in the Future of War?
War in and of itself is already a gray area when it comes to ethics and morality. Bring on machinery with autonomous decision making and it’s enough to bring eery chills reminiscent of a scary movie. One of the things that has made the headlines in recent warfare in Ukraine is the use of drones at a higher rate than has been used in modern conventional warfare. Ukraine and Russia are both engaged in drone warfare and using drones for strategic strikes.
Drones are part human controlled and essentially part robot and have AI baked in. What will the future look like though? Robots making their own decisions to strike? Completely autonomous flying drones and subs? There are various technologies being worked on as we speak to do exactly these things. Algorithmic bias becomes a much more cautionary tale when life and death decisions are made autonomously by machines.
Just this month Palantir was allocated a $229 million contract to assess the state of AI for the US Army Research Laboratory. That is just one branch of the military and one contract. The military as a whole is making huge investments in this area. In a Government Accountability Office report to Congressional Committees, it stated that “Joint Artificial Intelligence Center’s budget increased from $89 million in fiscal year 2019 to $242.5 million in fiscal year 2020, to $278.2 million for fiscal year 2021.” That is a 300% increase from 2019.
Here is an infographic taken from that report that summarizes the intended uses of AI.
So, how can AI in warfare exist ethically? Most of the suggestions I see suggest never removing a human from the loop in some form or fashion. Drones have the ability these days to operate nearly autonomously. U.S. Naval Institute mentions being very intentional about not removing a human from the loop because AI could still lack the intuition in nuanced scenarios that can escalate conflict past what is necessary. Even in the above infographic it clearly emphasizes the expert knowledge, which is the human element. Another important suggestion for ethical AI is not so different from when you train non-military models and that is to ensure equitable outcomes and reduce bias. With military technology, you want to be able to identify a target, but how you do that should not be inclusive of racial bias. Traceability and reliability were also mentioned as ways to employ AI more ethically according to a National Defense Magazine article. This makes sense that soldiers responsible should have the right education and training and that sufficient testing should be undertaken before use in conflict.
The converse argument here is, if we are ‘ethical’ in warfare, does that mean our adversaries will play by those same rules? If a human in the loop causes hesitation or pause that machinery operating autonomously on AI didn’t have, could that be catastrophic in wartime? Capabilities of our adversaries tend to dictate the needs of our military technologies being developed in Research and Development, embedded within the very contract requirements.
Let’s hope we will all get to remain military ethicists, keeping a human in the loop helps to protect against known deficiencies and biases inherent in AI. Data science models are built with uncertainty but when it comes to human life, special care must be taken. I’m glad to see Congressional Briefings that at least indicate we are thinking about this type of care and not ignoring the potential harms. I think it’s very possible that even though war is messy and murky with ethics, to be intentional on ethical choices with AI while still protecting and defending our interests as a nation…but I’m also not sure we want to be the last to create autonomous robot weapons, just in case. So, exploring technology and deploying thoughtfully appears to be the right balance.
What Differential Privacy in the 2020 Decennial Census Means for Researchers: Anonymous | October 8, 2022
Federal Law mandates that the United States Census records must remain confidential for 72 years, but they’re also required to release statistics for social science researchers, businesses, and local governments. The Census has tried many options for releasing granular statistics while protecting privacy, and for the 2020 Census they’re utilizing Differential Privacy (Ruggles, 2022). The most granular data that the Census will publish is its block level data – which in some cases is actual city blocks but in others is just a small region. To protect individual identities within each block, Differential Privacy will add noise to the statistics produced. This noise has caused concern for researchers and people using the data. This post is about how to spot some of the noise, and how to work with the data knowing that there is going to be noise.
Noise from differential privacy should impact low population blocks and subsets of people – such as minority groups who will have low population counts (Garfinkel, 2018). In the block level data, this is obvious in some blocks that shouldn’t have any people, or have people but no households (Wines, 2022). Block 1002 is in downtown Chicago and consists of just a bend in the river, the census says that 14 people live there. There are no homes there, so it’s obvious that these people are a result of noise from Differential Privacy. Noise like this might concern data scientists, but it should affect most statistical analyses like forms of outlier control or post-processing (Boyd, 2022). It shouldn’t negatively impact most research. So if you spot noise, don’t worry, it’s an error (purposefully).
The noise produced by Differential Privacy does affect research done on groups with small populations though. Individuals in small population groups, like Native American Tribes, are more easily identified in aggregate statistics so their stats will receive more noise to protect their identities noise (National Congress of American Indians, 2021). For these reasons, researchers at the National Congress of American Indians and the Alaska Federation of Natives have asked the Census for ways to access the unmodified statistics. Their work often requires having precise measurements of small population groups that are known to be heavily impacted by noise (National Congress of American Indians, 2021). If you think that this might impact your research, consult with an expert in Differential Privacy regarding your research.
The Census’ Differential Privacy implementation should improve privacy protection without impacting research results substantially. Attentive scientists will still find irregularities in the data, and some studies will be difficult to complete with the Differentially Private results, so it is important to understand how Differential Privacy has impacted the dataset.
Sources:
Boyd, Danah and Sarathy, Jayshree, Differential Perspectives: Epistemic Disconnects Surrounding the US Census Bureau’s Use of Differential Privacy (March 15, 2022). Harvard Data Science Review (Forthcoming). Available at SSRN: https://ssrn.com/abstract=4077426
National Congress of American Indians. “Differential Privacy and the 2020 Census: A Guide to the Data and Impacts on American Indian/Alaska Native Tribal Nations.” National Congress of American Indians Policy Research Center. May 2021.
Ruggles, Steven, et al. “Differential Privacy and Census Data: Implications for Social and Economic Research.” AEA Papers and Proceedings, vol. 109, 2019, pp. 403–08. JSTOR, https://www.jstor.org/stable/26723980. Accessed 7 Oct. 2022.
Simson L. Garfinkel, John M. Abowd, and Sarah Powazek. “Issues Encountered Deploying Differential Privacy.” In Proceedings of the 2018 Workshop on Privacy in the Electronic Society (WPES’18). Association for Computing Machinery, New York, NY, USA, pages 133–137. 2018. https://doi-org.libproxy.berkeley.edu/10.1145/3267323.3268949
Wines, Michael. “The 2020 Census Suggests That People Live Underwater. There’s a Reason.” New York Times. April 21st, 2022. https://www.nytimes.com/2022/04/21/us/census-data-privacy-concerns.html
Caught in the Stat – Using Data to Detect Cheaters Anonymous | October 8, 2022
In the world of shoe computers and super engines, is it possible to catch cheaters in chess and other fields with only an algorithm?
Setting the Board
On Sept 4th, 2022, the world’s greatest chess player (arguably of all time), Magnus Carlsen, lost to a 19-year old upcoming American player with far less name recognition – Hans Niemann.
Carlsen then immediately withdrew from the chess tournament, in a move that confused many onlookers. Two weeks later, in an online tournament with a prize pool of $500,000, Carlsen this time resigned immediately after the game began, in a move termed by many as a protest. Commentators stirred rumors that Carlsen suspected his opponent of cheating, especially after a suspicious-looking tweet.
Following this, a number of the sport’s most famous players and streamers took to the internet to share opinions on this divisive issue. Suspected cheating in chess is treated as a big deal as it potentially threatens the entirety of the sport and fans who admire it. While it’s well-established that the best players in the world still cannot compete with chess-playing software programs today, it is definitively against the rules to receive any assistance at all from a bot at any point during a match.
In today’s world, where even an outdated smartphone or laptop can crush Carlsen himself, catching such cheating can be a difficult task. In my experience playing chess in statewide tournaments in high school, it surprised me that players didn’t have their devices confiscated when entering the tournament area, and as one might expect, there were no metal detectors or similar scanners. At the highest level of competition, there may sometimes be both preventive measures taken, but it’s far from a sure bet.
Moreover, individuals determined to get an edge are often willing to go to creative lengths to do so. For instance, many articles have discussed devices that players can wear in shoes and receive signals in the form of vibrations by a small processor. ( https://boingboing.net/2022/09/08/chess-cheating-gadget-made-with-a-raspberry-pi-zero.html) Not to mention, many games in recent years are played entirely online, broadening the potential for abuse by digital programs flying under the radar of game proctors.
Here Comes the Data
If traditional anti-cheating monitoring isn’t likely to catch anyone in the act, how can data science step in to save the day?
As mentioned above, there are several chess-playing programs that have become well-known for their stellar win rate and versatility – two famous programs are named AlphaZero and Stockfish. Popular chess websites like Chess.com utilize these programs in embedded features for analyzing games for every turn to see how both players are performing during the game. These can also be used in post-game analysis to examine which moves by either side were relatively strong or weak. The abundant availability of these tools means that any bystander can statistically examine matches to see how well each player performed during a particular game compared to the “perfect” computer.
AlphaZero is an ML program written using Monte Carlo Tree Search. Very interesting detail here.
Armed with this as a tool, we can analyze all of history’s recorded games to understand player potential. How well do history’s greatest chess players compare to the bots?
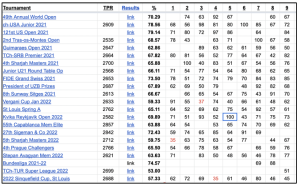
Image credit Yosha Iglesias – link to video below.
The graphic above details the “hit-rate” of some of the most famous players in history. This rate can be defined as the % of moves made over the course of a chess game that would align with what a top-performing bot would do at each move in the game, out of all the moves played. So if a chess Grandmaster makes 30 perfect moves out of 40 in a game, that game is scored at 75%. Since nearly all of a top-level chess player’s games are published in public record, this enables analysts the ability to build a library of games to compare behavior from match to match.
FM (FIDE Master) Yosha Iglesias has done just that, cataloging Niemann’s games and looking for anomalies. Using this method of analysis, she has expressed concern over a number of Niemann’s games, including those previously mentioned. Professor of Computer Science Kenneth Reagan at the University of Buffalo has also published research in a similar vein. The gist of their analysis centers around the idea that for chess cheaters, their performance in some games is so far above the benchmark and compared to their other games, or the entire body of published games, is a statistical near-impossibility to be performing that similarly to a computer without assistance.
While seemingly a very conditional or abstract argument, some organizations are already utilizing these analyses to place a ban on Niemann competing in any titled or paid tournaments in the future. Chess.com has been a leader in the charge, and on October 5th released a 72-page report accusing Niemann of cheating in over 100+ games, citing cheating-detection methodology with techniques including, “Looking at the statistical significance of the results (ex. “1 in a million chance of happening naturally”).
So what?
Cheating as an issue goes beyond chess. It threatens to undermine the hard work that many players put into their competitions, and at an organizational level, can cause billions of dollars of damage to victims due to corruption in industries like banking. For example, one mathematician used statistics to help establish how a speedrun in the multi-platform video game Minecraft was virtually guaranteed to not be on the base game due to having too much luck (natural odds of 1 in 2.0 * 1022), months before the player actually confessed. And in a broader sense, statistical principles like Benford’s law can be used to detect tax fraud in companies like Enron through their tax reports.
As long as human nature remains relatively the same, it’s likely that some individuals will try to take a shortcut and cheat wherever possible. And in today’s world, where it’s increasingly difficult to detect cheating through conventional means, data and statistical analysis are a vital tool to keep in the toolbelt. While those less familiar with this type of statistical determination may be more skeptical of these types of findings, further education and math diplomacy is needed from data advocates to illustrate their efficacy.