Saving the Future of Phone Calls – The Fight to Stop Robocalls
By Anonymous | July 5, 2019
“Hello, this is the IRS. I am calling to inform you of an urgent lawsuit! You are being sued for failing to pay taxes and we have a warrant out for your arrest. Please call this number back immediately!”
The familiar noisy background laced with thinly veiled threats is a message many are unfortunately accustomed to. Robocalls are a pervasive annoyance that has become the top consumer complaint to the Federal Trade Commission (FTC). And despite robocalls being prohibited by law, Americans were bombarded by a record breaking 4.4 billion robocalls in June 2019. That’s 145 million calls per day, 13 calls per person!
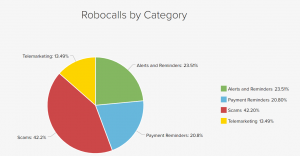
Figure 1: YouMail Robocall Index: https://robocallindex.com/
So, how does robocallers obtain phone number anyways? Most often, they acquire numbers from third party data providers, who in turn acquired numbers from a variety of avenues that everyday users may not be aware are collecting and selling their data. Some of these sources include:
- Toll free (1-800) numbers that employ caller ID which can collect phone numbers
- Entries into contests where users provided phone numbers in the process
- Applications for credit
- Contributions to charities where users provided phone numbers in the process
Methods of manipulating users into giving up personal information have evolved over the years as well. Robocalls can disguise their numbers to appear as a local telephone number with neighboring area codes to trick users into picking up unfamiliar calls outside of their personal contacts. The variety of robocallers disguising themselves as government agencies, municipal utility providers, or even hospital staff to scam users into providing personal information has grown to such an astonishing extent that lawmakers are now paying attention.

Figure 2: FTC Phone Scams: https://www.consumer.ftc.gov/articles/0076-phone-scams
In November 2018, the Federal Communications Commission (FCC) called on carriers to develop an industry-wide standard to screen and block robocalls. In particular, the FCC urged carriers to adopt the SHAKEN (Secure Handling of Asserted information using toKENs) and STIR (Secure Telephone Identity Revisited) frameworks by the end of 2019. In particular, SHAKEN/STIR frameworks employs secure digital certificates to validate that calls are from the purported source and has not been spoofed. Each telephone service provider must obtain a digital certificate from a certified authority and this enables called parties to verify the accuracy of the calling number.
Furthermore, in January 2019, Senators Edward J. Markey and John Thune introduced the Traced Act that aims to require all telephone service providers, including those over the internet such as Google Voice or Skype, to adopt similar call authentication technologies.
Together, the collective drive by private industry and regulatory efforts will make it harder for the majority of robocallers to spam consumers at the touch of a button. Like spam emails, calls with suspicious or unverified origins can be traced and blocked en masse. And though these recent tactics are certainly a step in the right direction for consumer protection, some fear that historically underserved communicated might not upgrade in time and be risk being further isolated. Rural areas that often rely on older landlines will foreseeably struggle to adopt the new technology due to outdated equipment and cost to implement. Immigrant communities who make and receive international calls to foreign countries might be subjected to higher levels of discrimination as international calls cannot yet be fully authenticated. This means their calls may be more likely to be labeled as fraud and increased targeting by robocall operatives that will exploit this gap in technology to scam an already vulnerable population.
As the world continues to evolve with newer technology, it’s important to not only think about who will benefit from these changes, but also who will be left behind. In this case, as the FCC and private industry work together to protect consumers, they should also seek to mitigate the risk of scam and spam robocalls targeting vulnerable communities. One way to accomplish this is to work with other regulatory agencies, such as the Housing and Urban Development department, to create long term and sustainable incentives within rural areas to modernize their infrastructure. Another way is for private industries who are vested in international businesses to continue working closely with regulators to develop a global SHAKEN/STIR standard that protects an increasingly globalized world. Afterall, robocalls are hardly a uniquely American phenomenon. However, taking the lead in safeguarding the next generation can be a defining American trademark.
Bibliography
- “How Do Robo-Callers and Telemarketers Have My Cell Number Anyway?” BBB, www.bbb.org/acadiana/news-events/news-releases/2017/04/how-do-robo-callers-and-telemarketers-have-my-cell-number-anyway/.
- “How to Know It’s Really the IRS Calling or Knocking on Your Door.” Internal Revenue Service, www.irs.gov/newsroom/how-to-know-its-really-the-irs-calling-or-knocking-on-your-door
- “Phone Scams.” Consumer Information, 3 May 2019, www.consumer.ftc.gov/articles/0076-phone-scams.
- “Thune, Markey Reintroduce Bill to Crack Down on Illegal Robocall Scams.” Senator Ed Markey, 17 Jan. 2019, www.markey.senate.gov/news/press-releases/thune-markey-reintroduce-bill-to-crack-down-on-illegal-robocall-scams.
- Vigdor, Neil. “Want the Robocalls to Stop? Congress Does, Too.” The New York Times, The New York Times, 20 June 2019, www.nytimes.com/2019/06/20/us/politics/stopping-robocalls.html.
- “YouMail Robocall Index: June 2019 Nationwide Robocall Data.” Robocall Index, robocallindex.com/.