
Generalization Furthers Marginalization
By Meer Wu | June 18, 2022
In the world of big data where information is currency, people are interested in finding trends and patterns hidden within mountains of data. The cost of favoring these huge sets of data is that often, the relatively small amounts of data representing marginalized populations can often be overlooked and misused. How we currently deal with such limited data from marginalized groups is more a convenient convention than a true, fair representation. Two ways to better represent and understand marginalized groups through data is to ensure that they are proportionately represented and that each distinct group has its own category as opposed to being lumped together in analysis.
How do we currently deal with limited demographic data of marginalized groups?
Studies and experiments where the general population is of interest typically lack comprehensive data of marginalized groups. Marginalized populations are “those excluded from mainstream social, economic, educational, and/or cultural life,” including, but not limited to, people of color, the LGBTQIA+ community, and people with disabilities [[1]](#References:). There are a number of reasons that marginalized populations tend to have small sample sizes. Some common reasons include studies intentionally or unintentionally excluding their participation [[2]](#References:), people unwilling to disclose their identities in fear of potential discrimination, or the lack of quality survey design that accurately capture their identities [[3]](#References:). These groups with small sample sizes often end up being lumped together or excluded from the analysis altogether.
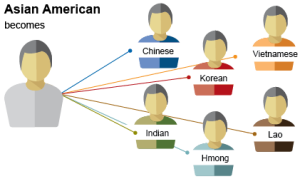
While aggregating or excluding data of marginalized groups ensures anonymity and/or helps establish statistically meaningful results, it can actually cause harm to them. Excluding or aggregating marginalized communities erases their identities, preventing access to fair policies guided by research, thus perpetuating the very systemic oppression that causes such exclusion in the first place. For example, the 1998 Current Population Survey reported that 21% Asian-Americans and Pacific Islanders (AAPI) lack health insurance, but a closer look into subpopulations within AAPI revealed that only 13% of Japanese-Americans actually lacked insurance coverage while 34% of Korean-Americans were uninsured [[4]](#References:). The exclusion of pregnant women in clinical research jeopardizes fetal safety and prevents their access to effective medical treatment [[5]](#References:). The results of marginalized groups should never be excluded and should not be lumped together so that each population’s results are not misrepresented.
What happens when we report unaggregated results instead?
Reporting unaggregated data, or data that is separated into small units, can help provide more accurate representation, which will help create better care, support, and policies for marginalized communities. On the other hand, it may pose potential threats to individual privacy when the sample size is too small. This is often used as the motivation to not report data of marginalized populations. While protecting anonymity is crucial, aggregation and exclusion should not be solutions to the problem. Instead, efforts should be made to increase sample sizes of marginalized groups so that they are proportionally represented in the data.
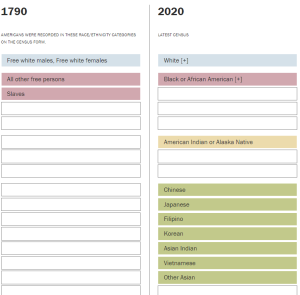
While there are statistical methods that will give accurate results without risking individual privacy, these methods are more reactive than preventative towards the actual problem at hand- the lack of good quality data from marginalized populations. One way to ensure a representative sample size is to create categories that are inclusive and representative of marginalized groups. A good classification system of racial, gender, and other categories should make visible populations that are more nuanced than what traditional demographic categories offer. For example, using multiple-choice selection and capturing changes in identities over time in surveys can better characterize the fluidity and complexities of gender identity and sexual orientation for the LGBTQ+ community [[3]](#References:). Having more comprehensive data of marginalized groups will help drive more inclusive policy decisions. Over time, the U.S. Census has been adding more robust racial categories to include more minority groups. Until 1860, American Indian was not recognized as a race category on the Census, and 2000 marked the first year the Census allowed respondents to select more than one race category. Fast forwarding to 2020, people who marked their race as Black or White were asked to describe their origins in more detail [[6]](#References:). The census has yet to create a non-binary gender category, but for the first time in 2021, U.S. Census Bureau’s Household Pulse Survey includes questions about sexual orientation and gender identity [[7]](#References:). This process will take time, but it will be time well spent.
[[1]](https://doi.org/10.1007/s10461-020-02920-3) Sevelius, J. M., Gutierrez-Mock, L., Zamudio-Haas, S., McCree, B., Ngo, A., Jackson, A., Clynes, C., Venegas, L., Salinas, A., Herrera, C., Stein, E., Operario, D., & Gamarel, K. (2020). Research with Marginalized Communities: Challenges to Continuity During the COVID-19 Pandemic. AIDS and Behavior, 24(7), 2009–2012. https://doi.org/10.1007/s10461-020-02920-3
[[2]](https://doi.org/10.1371/journal.pmed.0030019) Wendler, D., Kington, R., Madans, J., Wye, G. V., Christ-Schmidt, H., Pratt, L. A., Brawley, O. W., Gross, C. P., & Emanuel, E. (2006). Are Racial and Ethnic Minorities Less Willing to Participate in Health Research? PLoS Medicine, 3(2), e19. https://doi.org/10.1371/journal.pmed.0030019
[[3]](https://doi.org/10.1177/2053951720933286) Ruberg, B., & Ruelos, S. (2020). Data for queer lives: How LGBTQ gender and sexuality identities challenge norms of demographics. Big Data & Society, 7(1), 2053951720933286. https://doi.org/10.1177/2053951720933286
[[4]](http://healthpolicy.ucla.edu/publications/Documents/PDF/Racial%20and%20Ethnic%20Disparities%20in%20Access%20to%20Health%20Insurance%20and%20Health%20Care.pdf) Brown, E. R., Ojeda, V. D., Wyn, R., & Levan, R. (2000). Racial and Ethnic Disparities in Access to Health Insurance and Health Care. UCLA Center for Health Policy Research and The Henry J. Kaiser Family Foundation, 105.
[[5]](https://www.ncbi.nlm.nih.gov/pmc/articles/PMC2747530/?report=classic) Lyerly, A. D., Little, M. O., & Faden, R. (2008). The second wave: Toward responsible inclusion of pregnant women in research. International Journal of Feminist Approaches to Bioethics, 1(2), 5–22. https://doi.org/10.1353/ijf.0.0047
[[6]](https://www.pewresearch.org/fact-tank/2020/02/25/the-changing-categories-the-u-s-has-used-to-measure-race/) Brown, A. (2020, February 25). The changing categories the U.S. census has used to measure race. Pew Research Center. https://www.pewresearch.org/fact-tank/2020/02/25/the-changing-categories-the-u-s-has-used-to-measure-race/
[[7]](https://news.stlpublicradio.org/politics-issues/2020-03-17/the-2020-census-is-underway-but-nonbinary-and-gender-nonconforming-respondents-feel-counted-out) Schmid, E. (2020, March 17). The 2020 Census Is Underway, But Nonbinary And Gender-Nonconforming Respondents Feel Counted Out. STLPR. https://news.stlpublicradio.org/politics-issues/2020-03-17/the-2020-census-is-underway-but-nonbinary-and-gender-nonconforming-respondents-feel-counted-out