
Model Cards for Transparency
By Anonymous | October 8, 2021
In February of 2019, OpenAI wrote a blog post discussing results of their GPT-2 model (Radford et al., 2019). According to the release,
We’ve trained a large-scale unsupervised language model which generates coherent paragraphs of text, achieves state-of-the-art performance on many language modeling benchmarks, and performs rudimentary reading comprehension, machine translation, question answering, and summarization – all without task-specific training. -OpenAI
What makes the release of this model unique from an AI and data ethics perspective is that OpenAI decided not to release the model at that time and opened the blog by saying they would not do so because they were concerned about malicious uses of the technology. Examples of malicious uses were textual deep fakes; in other words, the ability of GPT-2 to give results that could reasonably appear to be human generated. The fact that the researchers purposefully chose to articulate malicious use cases and attempt an “experiment in responsible disclosure” (Radford et al., 2019) was a divergence then and continues to be a divergence from the common pattern of releasing machine learning models for end users to consume without making those users aware of ethical implications.

In January 2019, Margaret Mitchell and colleagues presented the paper Model Cards for Model Reporting at the Fairness, Accountability and Transparency (FAT*) conference (Mitchell et al., 2019). The key point of the paper is that machine learning systems have been found to have systemic bias and that bias is usually found by a human being that is affected by the bias inherent in the model. By releasing models with model cards which provide information such as: who created the model, when and with what software was the model created, what are the intended use cases, what training and evaluation data was used, what ethical considerations and caveats should be taken with the model, different users of the model can make an informed decision about whether it fits their use case without needing to seek out this additional information on their own.
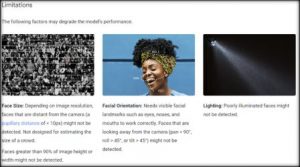
In particular with regulation for AI underway by governments like the EU and Brazil, it will be important to have a way to evaluate whether artificial intelligence algorithms are meeting the standards set by law and for companies to comply with the law. Modified model cards which display legal requirements and how the model complies helps identify whether a model meets the requirements. Further, while responsible and ethical AI is a huge topic, it is much better to have a model card which states ethical considerations than having to discover on one’s own. While in a perfect world the model cards would be generated automagically when the model is trained and the model would be required to meet certain metrics based on curated datasets, aspects of model cards, such as ethics and caveats, cannot be automated. Since at least some large companies will use AI models in multiple regulatory environments, the model cards will also serve as a way for the companies to keep track of how their models are performing in these different environments.
While the initial release of GPT-2 made a great step toward early identification of potential misuses of the model, searching for model cards on any of the large cloud providers yields almost no results in spite of the fact that customers are easily able to call cognitive services (image recognition, object detection, a wide range of natural language processing functions) it is left as an exercise for the user to identify what the ethical and policy implications of using the model is. Model cards as suggested by Mitchell et al. would help intentional users (people implementing the model) and unintentional users (the public or user of a product) have a much better understanding of the characteristics of the black box AI model.
References
Alec Radford, J. W. (2019, February 14). Better Language Models and Their Implications. Retrieved from OpenAI: https://openai.com/blog/better-language-models/
Margaret Mitchell, S. W. (2019, 1 14). Model Cards for Model Reporting. Retrieved from Arxiv.org: https://arxiv.org/pdf/1810.03993.pdf
Image Sources
The Robot-Powered Internet. Why 62% of companies will be using AI… | by Naman Raval | Chatbots Life