
AI Bias: Where Does It Come From and What Can We Do About It?
By Scott Gatzemeier | June 18, 2021
Artificial Intelligence (AI) bias is not a new topic but it is certainly a heavily debated and hot topic right now. AI can be an incredibly powerful tool that provides tremendous business value from automating or accelerating routine tasks to discovering insights not otherwise possible. We are in the big data era and most companies are working to take advantage of these new technologies. However, there are several examples of poor AI implementations that enable biases to infiltrate the system and undermine the purpose of using AI in the first place. A simple search on DuckDuckGo for ‘professional haircut’ vs ‘unprofessional haircut’ depicts a very clear gender and racial bias.
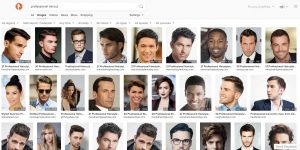
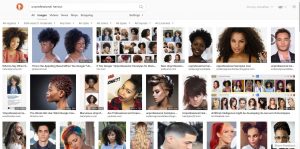
In this case, a picture is truly worth 1000 words. This gender and racial bias is not hard-coded in the algorithm by the developers maliciously. Rather it is a reflection of the word-to-picture associations that the algorithm picked up from the authors of the web commentary. So the AI is simply reflecting back historical societal biases to us in the images returned. If these biases are left unchecked by AI developers they are perpetuated. These perpetuated AI biases have proven to be especially harmful in several cases, such as Amazon’s Sexist Hiring Algorithm that inadvertently favored male candidates and the Racist Criminological Software COMPAS (Correctional Offender Management Profiling for Alternative Sanctions) where black defendants were 45% more likely to be assigned higher risk scores than white defendants.
Where does AI Bias Come From?
There are several potential sources of AI bias. First, AI will inherit the biases that are in the training data. (Training data is a collection of labeled information that is used to build a machine learning (ML) model. Through training data, an AI model learns to perform its task at a high level of accuracy.) Garbage in, Garbage out. AI reflects the views of the data that it is built on and can only be as objective as the data. Any historical data that is used would be subject to the same societal biases at the time the data was generated. When used to generate predictive AI, for example, this can lead to the perpetuation of stereotypes that impact decisions which can have real consequences and harms.
Next, most ML algorithms are built upon statistical math and look to make decisions based on distributions of data and key features that can be used to separate data points into categories or other items it associates together. Outliers that don’t fit the primary model tend to be weighted lower, especially when focusing only on the model accuracy. When working with people-focused data, often the outlier data points are in an already marginalized group. This is how biased AI can come from good clean non-biased data. AI is only able to learn about different biases (race, gender, etc.) if there is a high enough frequency of each group in the data set. The training data set must contain an adequate size for each group, otherwise this statistical bias can further perpetuate marginalizations.

Finally, most AI algorithms are built on correlation to the training data. As we know, correlation doesn’t always equal causation. The AI algorithm doesn’t understand what any of the inputs mean in context. For example, you get a few candidates from a particular school but you don’t hire them because you have a position freeze due to business conditions. The fact that they weren’t hired gets added to the training data. AI would start to correlate that school with bad candidates and potentially stop recommending candidates from that school even if they are great potentially because it doesn’t know the causation of why they weren’t selected.
What can we do about AI Bias?
Before applying AI to a problem, we need to ask what level of AI is appropriate? What should the role of AI be depending on the sensitivity and impact of the decision on people’s lives? Should it be an independent decision maker, a recommender system, or not used at all? Some companies are applying AI even if it is not at all suited to the task in question and other means would be more appropriate. So, there is a moral decision that needs to be made prior to implementing AI. Obed Louissaint the Senior Vice President of Transformation and Culture talks about “Augmented Intelligence”. This refers to leveraging the AI algorithms as “colleagues” to assist company leaders in making better decisions and better reasoning rather than replace human decision making. We also need to focus on the technical aspects of AI development and work to build models that are more robust against bias and against bias propagation. Developers need to focus on explainable, auditable, and transparent algorithms. When major decisions are made by humans the reasoning associated with that decision is an expectation and there is accountability. Algorithms should be subject to the same expectations, regardless of IP protection. Visualization tools that help to explain how AI works and the ‘why’ behind the conclusion that AI came to continue to be a major area of focus and opportunity.
In addition to AI transparency, there are emerging AI technologies such as Generative Adversarial Networks (GAN) that can be used to create synthetic unbiased training data based on parameters defined by the developer. Causal AI is another promising area that is building momentum and could provide cause and effect understanding to the algorithm. This could give AI some ‘common sense’ and prevent several of these issues.
AI is being adopted rapidly and the world is just beginning to capitalize on its potential. As Data Scientists, it is increasingly important to understand the sources of AI bias and continue to develop fair AI that prevents the social and discriminatory issues that arise from that bias.
References
- https://www.inc.com/guadalupe-gonzalez/amazon-artificial-intelligence-ai-hiring-tool-hr.html
- https://hbr.org/2020/10/ai-fairness-isnt-just-an-ethical-issue
- https://www.logically.ai/articles/5-examples-of-biased-ai
- https://towardsdatascience.com/why-your-ai-might-be-racist-and-what-to-do-about-it-c081288f600a
- https://medium.com/ai-for-people/the-ethics-of-algorithmic-fairness-aa394e12dc43
- https://towardsdatascience.com/survey-d4f168791e57
- https://techcrunch.com/2020/06/24/biased-ai-perpetuates-racial-injustice/
- https://towardsdatascience.com/reducing-ai-bias-with-synthetic-data-7bddc39f290d
- https://towardsdatascience.com/ai-is-flawed-heres-why-3a7e90c48878