Protecting your privacy through disposable personal information Anonymous | October 8, 2022
Protecting your privacy through disposable personal information The next time you sign up for a coupon code or make an online purchase, take these simple steps to protect yourself from fraud.
Paying for goods and services online is a common way that many of us conduct business nowadays. In addition to paying for these goods and services, whatever platform we chose to use on the web typically requires us to sign up for new accounts. This leaves the privacy of our sensitive personal information such as credit card details, name, email address at the mercy of the organizations or platforms we conduct business on. Using disposable personal information might be an easy way to safeguard our information in the event of a data breach.
What is disposable personal information?
Disposable or virtual card numbers are like physical credit cards but they only exist in a virtual form. A virtual credit card is a random 16-digit number associated with an already-existing credit card account. A virtual card becomes available for use immediately after being generated and is usually only valid for 10 minutes after. The original credit card number remains hidden from the merchant. This offers customers security by protecting information directly linked to bank accounts and can help limit how much information is accessible to fraudsters if a customer’s information is stolen in a phishing scam or a data breach.
Disposable email on the other hand, is a service that allows a registered user to receive emails at a temporary address that expires after a certain time period. A disposable email account has its own inbox, reply and forward functions. You should still be able to log into the app or service you’ve signed up for, but once the email address expires, you won’t be able to reset your password, delete your account, or do anything else using that email. Depending on the service, you might be able to change your disposable email address for a real one.
How do you create your own disposable information?
The easiest way to create your own virtual credit card is to request one through your credit card issuer. Many banks such as Capital One and Citi Bank offer virtual cards as a feature. Check with your financial institution if they have this service. Another option is to save your personal financial information, along with address on Google Chrome and allow the browser to automatically populate this information when you have to pay online. Google encrypts this information so that the merchant has no visibility to your sensitive information. Lastly, you can use an app like Privacy to generate virtual card numbers for online purchases. With this app, you can also create virtual cards for specific merchants and set spending limits on those cards, along with time limits on when they expire.
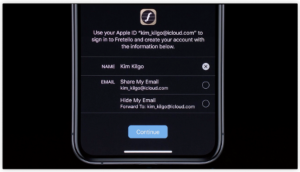
Creating disposable email addresses for web logins is straightforward if you have an Apple device. The option to use disposable email addresses is already an included feature. If the app or website you are using offers a Sign In With Apple option, you can register with your Apple ID, and select Hide My Email in the sharing option. By selecting this option, Apple generates a disposable email address for you, which relays messages to your main address.
You can also use services such as Guerilla Mail or 10-Minute Mail to generate a disposable email address.
An Artificial Intelligence (AI) Model Can Predict When You Will Die: Presenting a Case Study of Emerging Threats to Privacy and Ethics in the Healthcare Landscape Mili Gera | October 7, 2022
AI and big data are now part of sensitive-healthcare processes such as the initiation of end-of-life discussions. This raises novel data privacy and ethical concerns; the time is now to update or eliminate thoughts, designs, and processes which are most vulnerable.
An image showing the possibility of AI tools to identify patients using anonymized medical records. Figure by Dan Utter and SITN Boston via https://sitn.hms.harvard.edu/flash/2019/health-data-privacy/
Data Privacy and Ethical Concerns in the Digital Health Age
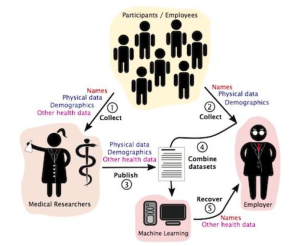
With the recent announcements of tech giants like Amazon and Google to merge or partner with healthcare organizations, legitimate concerns have arisen on what this may mean for data privacy and equity in the healthcare space [1,2]. In July 2022, Amazon announced that it had entered into a merger agreement with One Medical: a primary care organization with over a hundred virtual and in-person care locations spread throughout the country. In addition, just this week, Google announced its third provider-partnership with Desert Oasis Healthcare: a primary and specialty provider network serving patients in multiple California counties. Desert Oasis Healthcare is all set to pilot Care Studio, an AI-based healthcare data aggregator and search tool which Google built in partnership with one of the largest private healthcare systems in the US, Ascension [2]. Amazon, Google, and their care partners all profess the potential “game-changing” advances these partnerships will bring into the healthcare landscape, such as greater accessibility and efficiency. Industry pundits, however, are nervous about the risk to privacy and equity which will result from what they believe will be an unchecked mechanism of data-sharing and advanced technology use. In fact, several Senators, including Senator Amy Klobuchar (D-Minn.) have urged the Federal Trade Commission (FTC) to investigate Amazon’s $3.9 billion merger with One Medical [1]. In a letter to the FTC, Klobuchar has expressed concerns over the “sensitive data it would allow the company to accumulate” [1].
While Paul Muret, vice president and general manager of Care Studio at Google, stated that patient data shared with Google Health will only be used to provide services within Care Studio, Google does have a patient data-sharing past which it got in trouble for in 2019 [2]. The Amazon spokesperson on their matter was perhaps a bit more forthcoming when they stated that Amazon will not be sharing One Medical health information “without clear consent from the customer” [1]. With AI and big data technologies moving so swiftly into the most vulnerable part of our lives, it’s most likely that nobody, not even the biggest technology vendor who may implement algorithms or use big-data, understands what this may mean for privacy and equity. However, it is important that we start to build the muscle memory needed to tackle the new demands on privacy protection and healthcare ethics which the merger of technologies, data and healthcare will bring into our lives. To this end, we will look at one healthcare organization which has already implemented big data and advanced machine learning algorithms (simply put, the equations which generate the “intelligence” in Artificial Intelligence) in the care of their patients. We will examine the appropriateness behind the collection and aggregation of data as well as the usage of advanced technologies in their implementation. Where possible, we will try to map their processes to respected privacy and ethics frameworks to identify pitfalls. Since the purpose of this study is to spot potentially harmful instantiations of design, thoughts or processes, the discourse will lean towards exploring areas ripe for optimizations versus analyzing safeguards which already do exist. This is important to remember as this case study is a way to arm ourselves with new insights versus a way to admonish one particular organization for innovating first. The hope is that we will spark conversations around the need to evolve existing laws and guidelines that will preserve privacy and ethics in the world of AI and big data.
Health Data Privacy at the Hospital
In 2020, Stanford Hospital in Palo Alto, CA launched a pilot program often referred to as the Advanced Care Planning (ACP) model [3]. The technology behind the model is a Deep Learning algorithm trained on pediatric and adult patient data acquired between 1995 and 2014 from Stanford Hospital or Lucile Packard Children’s hospital. The purpose of the model is to improve the quality of end-of-life (also known as palliative) care by providing timely forecasters which can predict an individual’s death within a 3-12 month span from a given admission date. Starting with the launch of the pilot in 2020, the trained model automatically began to run on the data of all newly-admitted patients. To predict the mortality of a new admission, the model is fed twelve-months worth of the patient’s health data such as prescriptions, procedures, existing conditions, etc. As the original research paper on this technology states, the model has the potential to fill a care gap, since only half of “hospital admissions that need palliative care actually receive it” [4].
However, the implementation of the model is rife with data privacy concerns. To understand this a little better we can lean on the privacy taxonomy framework provided by Daniel J. Solove, a well-regarded privacy & law expert. Solove provides a way to spot potential privacy violations by reviewing four categories of activities which can cause the said harm: collection of data, processing of data, dissemination of data and what Solove refers to as invasion [5]. Solove states that the act of processing data for secondary use (in this case, using patient records to predict death versus providing care) violates privacy. He states, “secondary use generates fear and uncertainty over how one’s information will be used in the future, creating a sense of powerlessness and vulnerability” [5]. In addition, he argues it creates a “dignitary harm as it involves using information in ways to which a person does not consent and might not find desirable” [5].
A reasonable argument can be made here that palliative care is healthcare and therefore cannot be bucketed as a secondary use of one’s healthcare data. In addition, it can be argued that prognostic tools in palliative care already exist. However, this is exactly why discussions around privacy and specifically privacy and healthcare need a nuanced and detailed approach. Most if not all palliative predictors are used on patients who are already quite serious (often in the I.C.U). To illustrate why this is relevant, we can turn to the contextual integrity framework provided by Helen Nissenbaum, a professor and privacy expert at Cornell Tech. Nissenbaum argues that each sphere of an individual’s life comes with deeply entrenched expectations of information flows (or contextual norms) [6]. For example, an individual may be expecting and be okay with the informational norm of tra.c cameras capturing their image, but the opposite would be true for a public bathroom. She goes on to state that abandoning contextual integrity norms is akin to denying individuals the right to control their data, and logically then equal to violating their privacy. Mapping Nissenbaum’s explanation to our example, we can see that running Stanford’s ACP algorithm on let’s say for example, a mostly healthy pregnant patient, breaks information norms and therefore qualifies as a contextual integrity/secondary use problem. An additional point of note here is the importance of consent and autonomy in both Solove and Nissenbaum’s arguments. Ideas such as consent and autonomy are prominent components, and sometimes even definitions of privacy and may even provide mechanisms to avoid privacy violations.
In order for the prediction algorithm to work, patient data such as demographic details regarding age, race, gender and clinical descriptors such as prescriptions, past procedures etc., are combined to calculate the probability of patient death. Thousands of attributes about the patient can be aggregated in order to determine the likelihood of death ( in the train data set an average of 74 attributes were present per patient) [4]. Once the ACP model is run on a patient’s record, physicians get the opportunity to initiate advance care planning with the patients most at risk for dying within a year. Although it may seem harmless to combine and use data where the patient has already consented to its collection, Solove warns that data aggregation can have the effect of revealing new information in a way which leads to privacy harm [5]. One might argue that in the case of physicians, it is in fact their core responsibility to combine facts to reveal clinical truths. However, Solove argues, “aggregation’s power and scope are different in the Information Age” [5]. Combining data in such a way breaks expectations, and exposes data that an individual could not have anticipated would be known and may not want to be known. Certainly when it comes to the subject of dying, some cultures even believe that the “disclosure may eliminate hope” [7]. A thoughtful reflection of data and technology processes might help avoid such transgressions on autonomy.
Revisiting Ethical Concerns
For the Stanford model, the use of archived patient records for training the ACP algorithm was approved by what is known as an Institutional Review Board (IRB). The IRB is a committee responsible for the ethical research of human subjects and has the power to approve or reject studies in accordance with federal regulations. In addition, IRBs rely on the use of principles found in a set of guidelines called the Belmont Report to ensure that human subjects are treated ethically.
While the IRB most certainly reviewed the use of the training data, some of the most concerning facets of the Stanford process are on the flip side: that is, the patients on whom the model is used. The death prediction model is used on every admitted patient and without their prior consent. There are in fact strict rules that govern consent, privacy and use when it comes to healthcare data. The most prominent of these being the federal law known as The Health Insurance Portability and Accountability Act (HIPAA). HIPAA has many protections for consent, identifiable data and even standards such as minimum necessary use which prohibits exposure without a particular purpose. However, it also has exclusions for certain activities, such as research. It is most probable therefore that the Stanford process is well within the law. However, as other experts have pointed out, HIPAA “was enacted more than two decades ago, it did not account for the prominence of health apps, data held by non-HIPAA-covered entities, and other unique patient privacy issues that are now sparking concerns among providers and patients” [8]. In addition, industry experts have “called on regulators to update HIPAA to reflect modern-day issues” [8]. That being said, it might be a worthwhile exercise to assess how the process of running the ACP model on all admitted patients at Stanford hospital stacks up to the original ethical guidelines outlined in the Belmont Report. One detail to note is that the Belmont Report was created as a way to protect research subjects. However, as the creators of the model themselves have pointed out, the ACP process went live just after a validation study and before any double blind randomized controlled trials (the gold standard in medicine). Perhaps then, one can consider the Stanford process to be on the “research spectrum”.
One of the three criteria in the Belmont Report for the ethical treatment of human subjects is “respect for persons”: or the call for the treatment of individuals as autonomous agents [9]. In the realm of research this means that individuals are provided an opportunity for voluntary and informed consent. Doing otherwise is to call to question the decisional authority of any individual. In the ACP implementation at Stanford, there is a direct threat to self-governance as there is neither information nor consent. Instead an erroneous blanket assumption is made about patients’ needs around advance care planning and then served up as a proxy for consent. This flawed thinking is illustrated in a palliative care guideline which states that “many ethnic groups prefer not to be directly informed of a life-threatening diagnosis” [7].
An image from the CDC showing data practices as fundamental to the structure of health equity. https://www.cdc.gov/minorityhealth/publications/health_equity/index.html
Furthermore, in the Belmont Report, the ethic of “justice” requires equal distribution of benefits and burden to all research subjects [9]. The principle calls on the “the researcher [to verify] that the potential subject pool is appropriate for the research” [10]. Another worry with the implementation of the ACP model is that it was trained on data from a very specific patient population. The concern here is what kind of variances the model may not be prepared for and what kind of harm that can cause.
Looking Forward
Experts agree that the rapid growth of AI technologies along with private company ownership and implementation of AI tools will mean greater access to patient information. These facts alone will continue to raise ethical questions and data privacy concerns. As the AI clouds loom over the healthcare landscape, we must stop and reassess whether current designs, processes and even standards still protect the core tenets of privacy and equity. As Harvard Law Professor Glen Cohen puts it, when it comes to the use of AI in clinical decision-making, “even doctors are operating under the assumption that you do not disclose, and that’s not really something that has been defended or really thought about” [11]. We must prioritize the protection of privacy fundamentals such as consent, autonomy and dignity while retaining ethical integrity such as the equitable distribution of benefit and harm. As far as ethics and equity are concerned, Cohen goes on to state the importance of them being part of the design process as opposed to “being given an algorithm that’s already designed, ready to be implemented and say, okay, so should we do it, guys” [12]?
Is Ethical AI a possibility in the Future of War? Anonymous | October 8, 2022
Is Ethical AI a possibility in the Future of War?
War in and of itself is already a gray area when it comes to ethics and morality. Bring on machinery with autonomous decision making and it’s enough to bring eery chills reminiscent of a scary movie. One of the things that has made the headlines in recent warfare in Ukraine is the use of drones at a higher rate than has been used in modern conventional warfare. Ukraine and Russia are both engaged in drone warfare and using drones for strategic strikes.
Drones are part human controlled and essentially part robot and have AI baked in. What will the future look like though? Robots making their own decisions to strike? Completely autonomous flying drones and subs? There are various technologies being worked on as we speak to do exactly these things. Algorithmic bias becomes a much more cautionary tale when life and death decisions are made autonomously by machines.
Just this month Palantir was allocated a $229 million contract to assess the state of AI for the US Army Research Laboratory. That is just one branch of the military and one contract. The military as a whole is making huge investments in this area. In a Government Accountability Office report to Congressional Committees, it stated that “Joint Artificial Intelligence Center’s budget increased from $89 million in fiscal year 2019 to $242.5 million in fiscal year 2020, to $278.2 million for fiscal year 2021.” That is a 300% increase from 2019.
Here is an infographic taken from that report that summarizes the intended uses of AI.
So, how can AI in warfare exist ethically? Most of the suggestions I see suggest never removing a human from the loop in some form or fashion. Drones have the ability these days to operate nearly autonomously. U.S. Naval Institute mentions being very intentional about not removing a human from the loop because AI could still lack the intuition in nuanced scenarios that can escalate conflict past what is necessary. Even in the above infographic it clearly emphasizes the expert knowledge, which is the human element. Another important suggestion for ethical AI is not so different from when you train non-military models and that is to ensure equitable outcomes and reduce bias. With military technology, you want to be able to identify a target, but how you do that should not be inclusive of racial bias. Traceability and reliability were also mentioned as ways to employ AI more ethically according to a National Defense Magazine article. This makes sense that soldiers responsible should have the right education and training and that sufficient testing should be undertaken before use in conflict.
The converse argument here is, if we are ‘ethical’ in warfare, does that mean our adversaries will play by those same rules? If a human in the loop causes hesitation or pause that machinery operating autonomously on AI didn’t have, could that be catastrophic in wartime? Capabilities of our adversaries tend to dictate the needs of our military technologies being developed in Research and Development, embedded within the very contract requirements.
Let’s hope we will all get to remain military ethicists, keeping a human in the loop helps to protect against known deficiencies and biases inherent in AI. Data science models are built with uncertainty but when it comes to human life, special care must be taken. I’m glad to see Congressional Briefings that at least indicate we are thinking about this type of care and not ignoring the potential harms. I think it’s very possible that even though war is messy and murky with ethics, to be intentional on ethical choices with AI while still protecting and defending our interests as a nation…but I’m also not sure we want to be the last to create autonomous robot weapons, just in case. So, exploring technology and deploying thoughtfully appears to be the right balance.
What Differential Privacy in the 2020 Decennial Census Means for Researchers: Anonymous | October 8, 2022
Federal Law mandates that the United States Census records must remain confidential for 72 years, but they’re also required to release statistics for social science researchers, businesses, and local governments. The Census has tried many options for releasing granular statistics while protecting privacy, and for the 2020 Census they’re utilizing Differential Privacy (Ruggles, 2022). The most granular data that the Census will publish is its block level data – which in some cases is actual city blocks but in others is just a small region. To protect individual identities within each block, Differential Privacy will add noise to the statistics produced. This noise has caused concern for researchers and people using the data. This post is about how to spot some of the noise, and how to work with the data knowing that there is going to be noise.
Noise from differential privacy should impact low population blocks and subsets of people – such as minority groups who will have low population counts (Garfinkel, 2018). In the block level data, this is obvious in some blocks that shouldn’t have any people, or have people but no households (Wines, 2022). Block 1002 is in downtown Chicago and consists of just a bend in the river, the census says that 14 people live there. There are no homes there, so it’s obvious that these people are a result of noise from Differential Privacy. Noise like this might concern data scientists, but it should affect most statistical analyses like forms of outlier control or post-processing (Boyd, 2022). It shouldn’t negatively impact most research. So if you spot noise, don’t worry, it’s an error (purposefully).
The noise produced by Differential Privacy does affect research done on groups with small populations though. Individuals in small population groups, like Native American Tribes, are more easily identified in aggregate statistics so their stats will receive more noise to protect their identities noise (National Congress of American Indians, 2021). For these reasons, researchers at the National Congress of American Indians and the Alaska Federation of Natives have asked the Census for ways to access the unmodified statistics. Their work often requires having precise measurements of small population groups that are known to be heavily impacted by noise (National Congress of American Indians, 2021). If you think that this might impact your research, consult with an expert in Differential Privacy regarding your research.
The Census’ Differential Privacy implementation should improve privacy protection without impacting research results substantially. Attentive scientists will still find irregularities in the data, and some studies will be difficult to complete with the Differentially Private results, so it is important to understand how Differential Privacy has impacted the dataset.
Sources:
Boyd, Danah and Sarathy, Jayshree, Differential Perspectives: Epistemic Disconnects Surrounding the US Census Bureau’s Use of Differential Privacy (March 15, 2022). Harvard Data Science Review (Forthcoming). Available at SSRN: https://ssrn.com/abstract=4077426
National Congress of American Indians. “Differential Privacy and the 2020 Census: A Guide to the Data and Impacts on American Indian/Alaska Native Tribal Nations.” National Congress of American Indians Policy Research Center. May 2021.
Ruggles, Steven, et al. “Differential Privacy and Census Data: Implications for Social and Economic Research.” AEA Papers and Proceedings, vol. 109, 2019, pp. 403–08. JSTOR, https://www.jstor.org/stable/26723980. Accessed 7 Oct. 2022.
Simson L. Garfinkel, John M. Abowd, and Sarah Powazek. “Issues Encountered Deploying Differential Privacy.” In Proceedings of the 2018 Workshop on Privacy in the Electronic Society (WPES’18). Association for Computing Machinery, New York, NY, USA, pages 133–137. 2018. https://doi-org.libproxy.berkeley.edu/10.1145/3267323.3268949
Wines, Michael. “The 2020 Census Suggests That People Live Underwater. There’s a Reason.” New York Times. April 21st, 2022. https://www.nytimes.com/2022/04/21/us/census-data-privacy-concerns.html
Caught in the Stat – Using Data to Detect Cheaters Anonymous | October 8, 2022
In the world of shoe computers and super engines, is it possible to catch cheaters in chess and other fields with only an algorithm?
Setting the Board
On Sept 4th, 2022, the world’s greatest chess player (arguably of all time), Magnus Carlsen, lost to a 19-year old upcoming American player with far less name recognition – Hans Niemann.
Carlsen then immediately withdrew from the chess tournament, in a move that confused many onlookers. Two weeks later, in an online tournament with a prize pool of $500,000, Carlsen this time resigned immediately after the game began, in a move termed by many as a protest. Commentators stirred rumors that Carlsen suspected his opponent of cheating, especially after a suspicious-looking tweet.
Following this, a number of the sport’s most famous players and streamers took to the internet to share opinions on this divisive issue. Suspected cheating in chess is treated as a big deal as it potentially threatens the entirety of the sport and fans who admire it. While it’s well-established that the best players in the world still cannot compete with chess-playing software programs today, it is definitively against the rules to receive any assistance at all from a bot at any point during a match.
In today’s world, where even an outdated smartphone or laptop can crush Carlsen himself, catching such cheating can be a difficult task. In my experience playing chess in statewide tournaments in high school, it surprised me that players didn’t have their devices confiscated when entering the tournament area, and as one might expect, there were no metal detectors or similar scanners. At the highest level of competition, there may sometimes be both preventive measures taken, but it’s far from a sure bet.
Moreover, individuals determined to get an edge are often willing to go to creative lengths to do so. For instance, many articles have discussed devices that players can wear in shoes and receive signals in the form of vibrations by a small processor. ( https://boingboing.net/2022/09/08/chess-cheating-gadget-made-with-a-raspberry-pi-zero.html) Not to mention, many games in recent years are played entirely online, broadening the potential for abuse by digital programs flying under the radar of game proctors.
Here Comes the Data
If traditional anti-cheating monitoring isn’t likely to catch anyone in the act, how can data science step in to save the day?
As mentioned above, there are several chess-playing programs that have become well-known for their stellar win rate and versatility – two famous programs are named AlphaZero and Stockfish. Popular chess websites like Chess.com utilize these programs in embedded features for analyzing games for every turn to see how both players are performing during the game. These can also be used in post-game analysis to examine which moves by either side were relatively strong or weak. The abundant availability of these tools means that any bystander can statistically examine matches to see how well each player performed during a particular game compared to the “perfect” computer.
AlphaZero is an ML program written using Monte Carlo Tree Search. Very interesting detail here.
Armed with this as a tool, we can analyze all of history’s recorded games to understand player potential. How well do history’s greatest chess players compare to the bots?
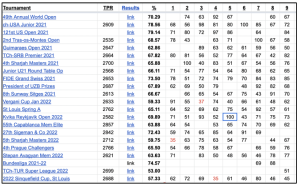
Image credit Yosha Iglesias – link to video below.
The graphic above details the “hit-rate” of some of the most famous players in history. This rate can be defined as the % of moves made over the course of a chess game that would align with what a top-performing bot would do at each move in the game, out of all the moves played. So if a chess Grandmaster makes 30 perfect moves out of 40 in a game, that game is scored at 75%. Since nearly all of a top-level chess player’s games are published in public record, this enables analysts the ability to build a library of games to compare behavior from match to match.
FM (FIDE Master) Yosha Iglesias has done just that, cataloging Niemann’s games and looking for anomalies. Using this method of analysis, she has expressed concern over a number of Niemann’s games, including those previously mentioned. Professor of Computer Science Kenneth Reagan at the University of Buffalo has also published research in a similar vein. The gist of their analysis centers around the idea that for chess cheaters, their performance in some games is so far above the benchmark and compared to their other games, or the entire body of published games, is a statistical near-impossibility to be performing that similarly to a computer without assistance.
While seemingly a very conditional or abstract argument, some organizations are already utilizing these analyses to place a ban on Niemann competing in any titled or paid tournaments in the future. Chess.com has been a leader in the charge, and on October 5th released a 72-page report accusing Niemann of cheating in over 100+ games, citing cheating-detection methodology with techniques including, “Looking at the statistical significance of the results (ex. “1 in a million chance of happening naturally”).
So what?
Cheating as an issue goes beyond chess. It threatens to undermine the hard work that many players put into their competitions, and at an organizational level, can cause billions of dollars of damage to victims due to corruption in industries like banking. For example, one mathematician used statistics to help establish how a speedrun in the multi-platform video game Minecraft was virtually guaranteed to not be on the base game due to having too much luck (natural odds of 1 in 2.0 * 1022), months before the player actually confessed. And in a broader sense, statistical principles like Benford’s law can be used to detect tax fraud in companies like Enron through their tax reports.
As long as human nature remains relatively the same, it’s likely that some individuals will try to take a shortcut and cheat wherever possible. And in today’s world, where it’s increasingly difficult to detect cheating through conventional means, data and statistical analysis are a vital tool to keep in the toolbelt. While those less familiar with this type of statistical determination may be more skeptical of these types of findings, further education and math diplomacy is needed from data advocates to illustrate their efficacy.
How to seek abortion care with a minimal data trail Jenna Morabito | July 7, 2022
Thinking like a criminal in a post Roe v. Wade country
America is starting to roll back human rights: law enforcement is already using facial recognition to arrest protestors, and could start using location and menstruation data to prosecute women seeking an abortion. It is important that people know what options they have to stay private, and are aware that privacy comes with significant challenges and inconveniences.
Step 1: Remove app permissions
This advice has been all over the internet since the Supreme Court repealed Roe v. Wade, but it bears repeating: request that your period tracking app deletes your data, close your account, and delete the app. Cycle tracking apps and other businesses have been caught selling health data to Facebook and other companies, giving law enforcement more places to find your data. Even if companies don’t sell your data, they will be bound by subpoena to turn it over to law enforcement in the event of an investigation. I am not a law professional, but my guess is that using a foreign-owned app isn’t enough either: the European-based cycle tracking app Clue might have to relinquish your data to US law enforcement under the EU-US Data Protection Umbrella Agreement. How to request erasure varies by app, but a tutorial on deleting your data from Flo can be found here and one method of tracking your cycles by hand can be found here.
Then, go through all your apps and remove as many permissions as you can. This isn’t a trivial task; I found multiple places in my phone settings to restrict apps’ data access, and had to go through each one individually. As part of removing permissions I turned off location tracking on my phone, but location can still be very accurately pinpointed with Wi-Fi location tracking (your phone communicating with every network on the street you’re walking down), and your general location is known to the sites that you visit through your IP address – which is a unique identifier to your device. The best way to disable Wi-Fi tracking is to turn off Wi-Fi on your phone, and hiding your IP address can be done by using a Virtual Private Network.
Step 2: Secure your web browsing
Step 2.1: Get a VPN
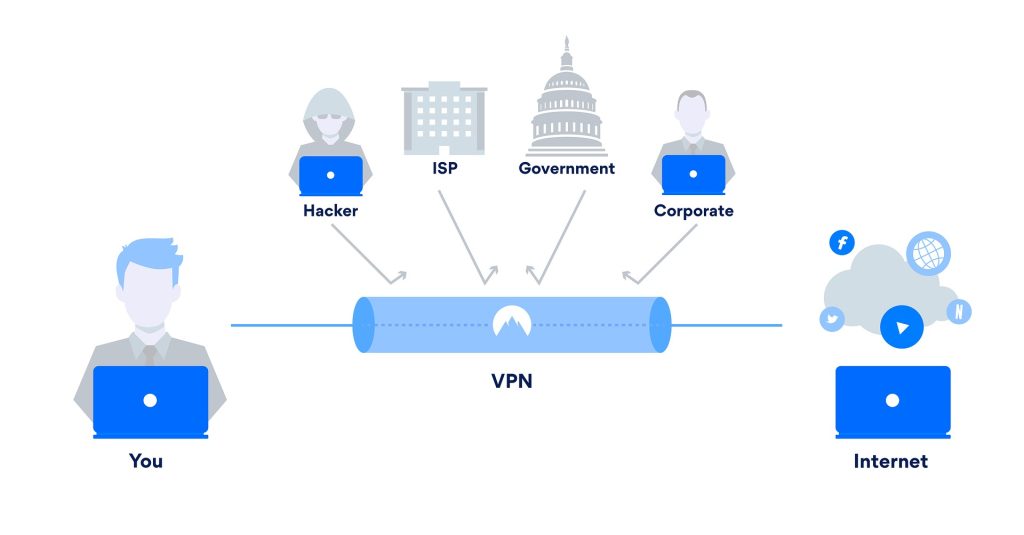
A Virtual Private Network, or VPN, is a privacy heavyweight. Without a VPN, the government, businesses, and other entities can track your IP address across websites and even see your activity on a website, depending on the security protocol of the specific site, meaning that law enforcement could see that you visited websites having to do with pregnancy or abortion. A VPN is your shield: you (and your unique IP address) connect to the VPN’s server, and the VPN forwards your request on, but with their IP address for the website to send information back to. In addition, they encrypt everything about your request. No one can see your IP address, what websites you visit, or what you do on those websites.
A VPN sends all your traffic through an encrypted tunnel.
Not all VPNs are created equal, though. As your shield they can see what websites you go to, and some VPNs turn around and sell that information. Others don’t sell it but do keep records of your activity, which means that we have the same subpoena problem as before, and so it’s important to use a VPN that doesn’t keep logs. There are a few; the one I use is NordVPN. I encourage you to do some research and find a good service for you, but Nord doesn’t keep logs, has a variety of security features, and can be bought with cash at places like Best Buy or Target, making it an anonymous purchase. They also have seamless integration with the collection of technologies called Tor, which makes the next step simpler. One thing to note though, is that if you are logged in to your Google account at the browser or device level, or use any Google apps on your phone, then Google sees and stores all your browsing data before it gets encrypted, bypassing the privacy that the VPN offers. Therefore, I suggest using Google services only when strictly necessary, and suggest using more privacy-focused services like the ones that I recommend in later sections.
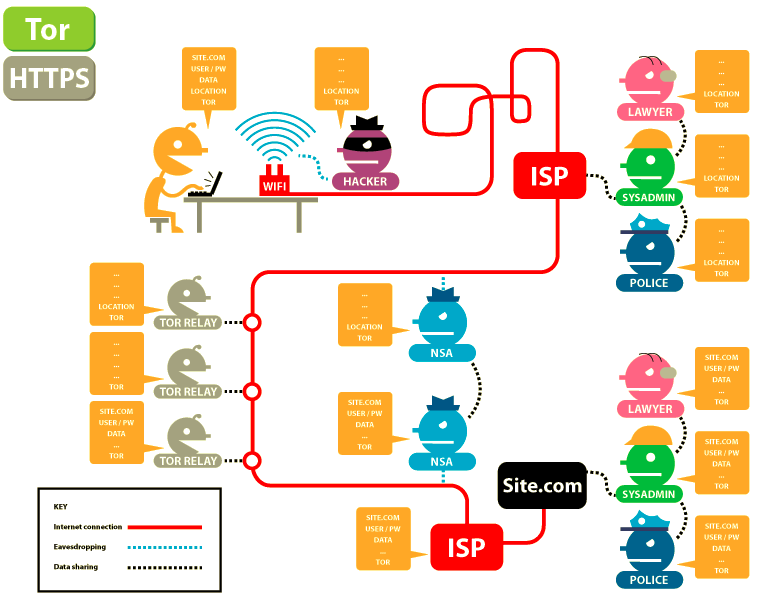
Step 2.2: Use Tor
Tor is two things: a networking system, and a special browser. The networking system works by bouncing your request around between three random servers, where one layer of encryption gets peeled off at each stop so that upon exiting the network, the website knows what your request is. Then, the information you requested is triple-encrypted and sent back to you along a different route.
To access the network system you download the Tor browser, or use the network through NordVPN or another service with Tor integration. Though Tor is a sophisticated technology that makes tracking people a headache, it’s not perfect. Cybernews.com puts the additional steps that should be taken when using Tor succinctly:
Don’t log into your usual accounts – especially Facebook or Google
Try not to follow any unique browsing patterns that may make you personally identifiable.
Turn the Tor Browser’s security level up to the max. This will disable JavaScript on all sites, disable many kinds of fonts and images, and make media like audio and video click-to-play. This level of security significantly decreases the amount of browser code that runs while displaying a web page, protecting you from various bugs and fingerprinting techniques.
Use the HTTPS Everywhere extension. This will ensure you’re only browsing HTTPS websites and protect the privacy of your data as it goes between the final node and the destination server.
As a general rule, never use BitTorrent over Tor. Although people illegally pirating copyrighted content may wish to obscure their real identity, BitTorrent is extraordinarily difficult to use in a way that does not reveal your real IP address. Tor is relatively slow, so BitTorrent is hardly worth using over Tor anyway.
Most importantly, always keep Tor Browser (and any extensions) updated, reducing your attack surface.
You shouldn’t log in to Facebook or Google because those sites are notorious for tracking you, but also because logging into any site with personally identifiable information is a clear indication that you’ve been there, much like using your keycard to enter your office building. I will discuss this more later, but this means that special precautions should be taken when ordering abortion pills online, as your shipping and payment information lead straight to you. In short you don’t need to use Tor every day, only when searching for sensitive information. For suggestions on a more casual privacy-focused browser, check out this list.
Additionally, you should always turn your VPN on before using Tor, otherwise you may attract your internet service provider’s suspicion. While Tor is legal to use and the New York Times even has a Tor-specific website so that people living under oppressive regimes can access outside news, Tor is known to facilitate serious crime: drug trafficking, weapons sales, even distributing child pornography. I feel significant discomfort with recommending that an average citizen use a technology that is in part sustained by truly evil crime, but what’s the appropriate balance between privacy and public safety if you can’t trust your government to protect basic human rights?
Step 3: Ditch Google
Google is ubiquitous, convenient, and free to use – although since you’re not paying with money, you’re paying with your data. I’m focusing on Google here since it’s so popular, but the type of data that Google collects is likely collected by other big companies, too.
Google Chrome and Google Search each know a surprising amount of information about you: your device’s timezone, language, privacy settings, and even what fonts you have installed; this collection of things comprises your browser’s potentially unique fingerprint, and you can check out yours here. According to RestorePrivacy.com there’s not a lot you can do about your smartphone’s fingerprint, but you can minimize digital fingerprinting on your computer by tinkering with settings and add-ons or changing browsers. The browser Brave offers built-in fingerprint protection as well as easy Tor access and seems like a good out-of-the-box option for those who don’t want to fuss, although I haven’t tried it myself.
Most notably, Chrome and Google Search store your browsing history, which law enforcement might then be able to access with a keyword warrant, identifying individuals who made searches deemed to be suspicious. To avoid getting attention when searching for abortion providers, you should switch to a search engine that logs the minimum amount of data and/or stores the log outside the U.S and EU. There isn’t any one silver bullet, but RestorePrivacy.com suggests a few privacy-focused search engines here.
Beyond just reading your emails, having a Google account signs you up for all sorts of tracking; check it out yourself at myactivity.google.com. I found YouTube videos that I’d watched years ago, every hole in the wall café I’ve ever been in; the information that Google has on me creates a fuller timeline of my life than my journal does. More private email services are less convenient and are all paid subscriptions, but a tutorial on how to evade regressive laws wouldn’t be complete without discussing communication technologies. This article does a good job laying out pros and cons of different email services as well as explaining which jurisdictions to look for: the U.S. and some European companies are subject to invasive requests from law enforcement, so even if Google stopped selling data to advertisers, users would still be at risk.
Finally, be careful where you send messages. Text messages are not encrypted, meaning that they can be read by your service provider. Signal is a free messaging app that only stores three things about you: “the phone number you registered with, the date and time you joined the service, and the date you last logged on” (RestorePrivacy.com). They don’t store who you talk to or what you talk about and they encrypt your message, making it a good place to create sensitive plans.
Step 4: Seek medical care (carefully)
With this knowledge, I hope that you can safely seek the care you need. With today’s level of surveillance I’m not confident that I even know all the ways that our movements are tracked once we leave the house: license plate scanners give our travel path in almost real-time, GPS-enabled cars do the same, so does calling an Uber, and so on. Assuming that you can drive 400+ miles to the nearest abortion clinic without detection, you’ll want to buy a simple burner phone for your travels so that mobile proximity data (what other mobile phones your phone has been near) don’t give you away, and I suppose that you should pay for your hotel room with a prepaid visa card that you bought in cash.
Or, if at all possible, get a friend living in a state where abortion is legal to buy the pills for you and ship them to you, so you can avoid revealing your payment information and address online. Coordinate with them on Signal and pay them back with a prepaid visa card.
Conclusion
It’s dystopian. The American government has abandoned its citizens in a new and exciting way and as always, has disproportionately harmed poor womxn. I know that this tutorial isn’t the most accessible since it requires time, good English, and computer literacy to implement. I know that privacy costs money: NordVPN charges $40-70 a year, a private email account is $20-50 a year, and that’s before the cost of an abortion or travel expenses.
However, I didn’t master all these technologies in a day, either. I’ve implemented – and continue to implement – more private practices around my data one at a time. The world is scary right now, but we can help each other get through it by sharing our expertise and resources. I hope that I’ve helped clarify how to take control of your data, which is a tedious process but empowering. We don’t owe corporations, and certainly not law enforcement, any of our intimate information.
“I can promise you that women working together – linked, informed, and educated – can bring peace and prosperity to this forsaken planet.” — Isabelle Allende
Roe v Wade Overturned: Creating Unforeseen Data Privacy Consequences? Anonymous | July 7, 2022
The Supreme Court’s jarring decision to overturn Roe v. Wade, banning abortion in many states across the country, has created an unforeseen consequence in data privacy. In an increasingly digital era, will data about abortions be used against women?
Data Privacy Concerns in The Aftermath of Roe v. Wade
The Supreme Court’s jarring decision to overturn Roe v. Wade has brought the United States back to an era before 1973. However, the increasingly digital world in 2022 is vastly different from that of 1973, with concerns that nobody knew existed until now. Nowadays, digital footprints are regularly used for legal prosecution, raising the concern that data may be used against those seeking abortions. In addition to call logs, texts, and other forms of communication, there now exists location specific data, payment records, and a whole host of information about abortion seeking women that did not exist in the past. What is even more frightening is the lack of protections and governance around this data. The question becomes, who will govern this new uncharted data territory?
The Current Landscape for Abortion Data Privacy
In the past,there have been several known cases that have used text messages and search history in abortion convictions. However, this data sphere will not grow to beyond basic forms of communication. For example, a simple Uber ride to an abortion clinic may be evidence in a legal case. However, the United States is not yet privy to the data privacy concerns that lie ahead. The Supreme Court deferring abortion to individual states presents a unique gray area for data governance regarding those abortions. Should data governance and protection come from the federal level of government? Or is this too a state’s decision to make? And who will relegate technology companies when it comes to collecting and protecting user data? These are all questions that are currently unanswered. In response to the overturning of Roe v. Wade, many companies have issued general public advisories to the public of how to best protect their abortion data, with figure 1 being a prominent example of this trend.
A Company trying its best to help users navigate data privacy for abortion related data.
Ethical and Privacy Concerns of Abortion Data
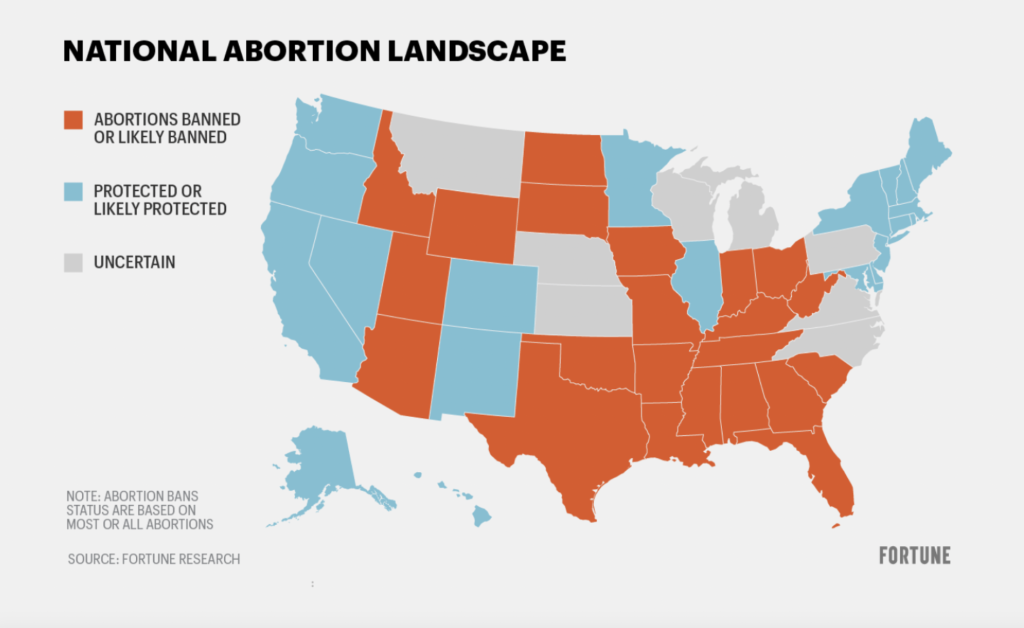
With the emergence of this new field of data privacy for abortion related data, there are several opportunities for womens’ data to be exploited that need to be further explored. These concerns are best explored through the lens ofSolove’s Taxonomy. Essentially, Solove’s Taxonomy divides potential data privacy concerns into several facets. In the context of our abortion related privacy concerns, some facets are more relevant than others. The first relevant facet is information processing, which covers concerns such as secondary use of data. In this case, it is entirely possible that sensitive data about abortions, for example from an app that tracks periods, can be sold, and exploited by a secondary party. The next relevant facet of Solove’s Taxonomy is information dissemination, which is perhaps the most relevant concern for abortion related data. This facet covers breach of privacy, as well as blackmail. For a user’s data that may be tied to an abortion, there is absolutely a chance that the confidentiality of this data can be breached. Additionally, if this data falls into the wrong hands, it can be used to blackmail users as well. Lastly, as found in figure 2, the country remains heavily divided on the issue of abortion. Another question that comes about from this is how will states share information about abortions if people are traveling over state lines to gain access to abortions? For example, if someone travels from Arizona to California to gain access to an abortion, how is information sharing going to work between the two states? There needs to be more concrete protections around the flow of information from state to state.
A country divided when it comes to the issue of abortion. How does information flow between these divided states?
What Lies Ahead
In this new era of outlawed abortions in parts of the country, there needs to be more proactive legislation and protects the privacy interests of individuals tied to an abortion. Perhaps the most concerning situation that requires protection is the bounty system some states, such as Texas, are employing to police abortions. Here, any citizen can file a lawsuit to report an abortion, and potentially win 10,000 USD. With a digital trail of abortion related data only growing further, how will someone’s data be kept safe to ensure it is not. Exploited or used against them? There remain major governance and ethical questions surrounding this issue that may take longer than expected to sort out.
AI For Gun Regulation: Not the Best Solution? Joyce Li | July 7, 2022
Though school districts are pouring money into AI-based gun detection products in light of recent shootings, widespread implementation of these products may not be overall beneficial for society.
Image 1: Gun-free sign outside of a school.
In the first 6 months of 2022, there have been at least 198 mass shootings in the United States. Especially in the light of the recent Highland Park Parade and Robb Elementary Uvalde shootings, many groups have begun lobbying for increased gun control regulations as a response to increasing gun violence throughout the country. In the meantime, schools and government agencies have turned their attention to AI products that can aid with gun detection. Existing technologies vary from AI camera feed scanners to 3D imaging and surveillance products. These products aim to detect guns quickly before a shooting happens; the idea is that if people and law enforcement are notified that there is a gun in the area, people can get to safety before any harm can be done. However, with technical limitations along with the high prices associated with the technology, it is difficult to justify AI gun detection technology as the best solution to reducing gun violence in the US. Despite the beneficial intent behind these systems, there is much skepticism about whether or not these systems are ready for deployment.
Product Limitations
Many gun detection products are already on the market and actively being used by schools and government agencies. However, these products already have several limitations in their current use cases. For example, ZeroEyes is a product that scans school camera feeds using ML to identify up to 300 types of firearms. Because state-of-the-art algorithms are not quite at a stage where accuracy can be 100%, military veterans are employed by the company 24/7 to check whether flagged footage is correctly classified as guns. Despite how well the technology could work, a major issue with the system is that the algorithm is only trained to classify guns in plain sight. This brings into question how useful the technology really is, given that experienced shooters would not typically brandish their guns in plain sight when planning for a large-scale shooting.
Image 2: ZeroEyes gun detection example.
Another example is with the company Evolv, which an AI-based metal detector that aims to flag weapons in public spaces. The system is currently already being used by sports stadiums such as the SoFi Stadium and in North Carolina’s Charlotte-Mecklenburg’s school system as a scanner before people enter the area. When suspicious objects are detected, a bounding box is immediately drawn around the area where a person could be carrying the item, allowing security officers to continue with a manual pat-down. Again, despite the potential for the tool to reduce friction in the security process, there are still major technical limitations for the tool despite its establishment in the market. One major issue is that the AI still confuses other metal objects as guns, such as Google Chromebook — quite a large mistake to be making in a school setting. The fact is that ML models are nowhere near close to perfect still, and the fact that manual checks are still a large part of both mentioned products signals that gun-detection AI may not be ready for full adoption.
Ethical Implications
In addition to the technical limitations of state-of-the-art gun detection algorithms, there are many questions about how ethical such products are when put into use. The main concern is how to ensure that these safety tools can be equally and fairly accessed by everyone. The justice principle from the Belmont Principles emphasizes that benefits from a fair product should be distributed equally. Because these products have such steep costs ( for reference, ZeroEyes costs $5,000/month for 200 cameras and Evolv costs $5 million for 52 scanners), it does not seem that schools and other institutions from low-income communities can afford such security measures. These prices sees even more unfortunate given that areas with higher income inequality are more likely to see mass shootings. This also leads to the question of why school districts, which are already notoriously underfunded in the US government system, should have to spend extra money to ensure that students can simply stay safe at school.
According to another aspect of the Belmont principles, all subjects should be treated with respect, meaning that they should be treated autonomously and given the choice to participate in monitoring or to opt out. With widespread technology, to what extent should students or sports arena attendees be monitored? How does an institution get consent from these people to be scanned and to use their data to train machine learning algorithms? There has always been a balance to be discovered between privacy and security, but in the situation with gun detection AI, there seems to be no choice for people whether to opt in or out. This raises many questions as to how much these AI products could harm its users despite the proposed benefits.
Looking Forward
While AI technologies have the potential to be useful one day, it seems that they are not ready to be the optimal solution to ending gun violence in America. These solutions need to surpass current technical limitations, become scalable, and address many ethical questions before they become widespread. Companies and schools can spend their money better elsewhere in providing mental health resources for students and employees, donating money to support institutional security measures, and lobbying for more comprehensive gun control laws.
Pegasus, Phantom, and Privacy Kaavya Shah | July 7, 2022
NSO Group’s mythically monikered technologies are putting American privacy at risk, but tech users can rest assured for the time being.
The Israeli cybersecurity company develops surveillance technologies for government agencies.
Earlier this year, the New York Times broke news of the FBI’s secret use of NSO technologies, claiming it was purely to understand how leading cyberattack technologies function. However, there has been great controversy over the use of this software, with huge implications to personal privacy.
Who is NSO and what is Pegasus?
NSO Group is a cybersecurity company from Israel that creates technologies to “prevent and investigate terrorism and crime” (https://www.nsogroup.com). One of their more popular softwares is Pegasus, which can hack into the contents of any iPhone or Android without sending a suspicious link. This gives access to almost all of the contents on a phone, ranging from photos and messages, to location tracking and recording capabilities. However, there is one notable flaw in Pegasus – the Israeli government requires that by design, it cannot be used to hack into phones with an American number; this design prevents both Americans, and non-Americans, from surveilling on American phones.
This software has been incredibly useful to detect and prevent criminal and terrorist plots, but governments have also deployed it aganist journalists, activists, and protestors. Because of the many documented cases of NSO surveillance tools being used to spy, there is widespread apprehension of the creation and use of its technologies.
What is the FBI doing with it?
Given that Pegasus is inoperable on American numbers, why is there a conversation about NSO Group working with the FBI? In order for the American government to actually test out any software, NSO demonstrated a similar software called Phantom, which received special permission from the Israeli government to hack into American devices and could only be sold to American government agencies.
With this new software that could be used in America, the FBI and the Justice Department set out to determine if Phantom could be used in accordance with American wiretapping laws, strengthened by 4th Amendment’s constitutional protection from unreasonable searches and seizures. Consider CalECPA, the California Electronic Communications Privacy Act, which specifies that searching and seizing electronic information also requires a warrant that is supported by an affidavit; because of this, even if Phantom gives the technical capabilities to obtain information, there is still a high legal barrier to obtain a warrant.
However, there was public outrage over the fact that the FBI had purchased and used spyware from NSO. Due to this, the New York Times has filed a Freedom of Information lawsuit against the FBI, demanding that information on the FBI’s testing and use of NSO tools be released before August 31, 2022.
Should we be worried?
Ultimately, the FBI decided against purchasing Phantom from NSO Group to surveil Americans. In addition to this decision behind closed doors, in November of 2021, the Biden administration added NSO Group to the Commerce Department’s Entity List of blacklisted companies, severely limiting NSO’s ability to use American tech. This decision has been met with controversy, as the Israeli government took this as a political attack to the country, while the Biden administration argues that the decision was made purely on the basis of supporting human rights.
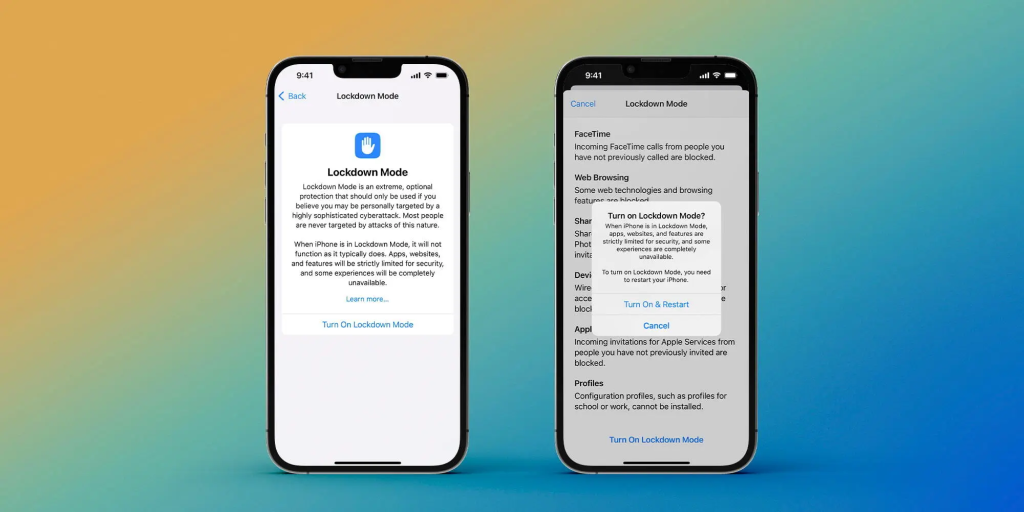
Lockdown Mode, a new feature in iOS 16, secures Apple devices from outsiders like NSO’s Pegasus.
Additionally, Apple users can rejoice, with the recent announcement of “Lockdown Mode” on July 6. Apple produced this security feature as a direct response to University of Toronto’s Citizen Lab’s research, which showed that Pegasus could hack into iPhones through the iMessage feature. This feature was added specifically for people who may fear a Pegasus or Phantom attack, resulting in extreme device functionality limitations that severely reduce the potential of a successful cyberattack, effectively strengthening your security. However, it is important to note that this feature will only benefit those who can actually afford the expensive Apple devices. While the Belmont Report’s principle of justice points out that ethical solutions should provide equal treatment to all people, technological improvements continue to be restricted due to their costs, widening the injustices of access to technology. So, even though there is a solution to protect individuals from Pegasus and Phantom attacks, ownership of these devices with these capabilities is entirely dependent upon a person’s disposable income.
NSO Group’s technologies are providing government agencies across the world with highly invasive cybersecurity technologies, with little to no regulation on the use of the softwares. However, for the time being, American cell phone owners–especially American iPhone owners–do not have to worry about a Phantom attack any time soon.
Data After Death: Taking Your Data Too Far Elias Saravia | July 7, 2022
With the rise of artificial intelligence, people’s personal data is now being exploited more than ever for profit in the entertainment industry, especially after their death. In this new technological wave, it is important to bring awareness to the ethical issues behind data collection and utilization of individuals after their death.
AI in Entertainment:
On December 20th, 2019, Star Wars: Rise of the Skywalker was released and utilized artificial intelligence technology known as a Deepfake to bring Princess Leia “back to life”, bringing both excitement and uneasiness to viewers following Carrie Fisher’s death on December 23rd, 2016. This summer 2022, Selena, a female Latin pop singer whose death was 27 years ago, will be releasing a new album with 3 new AI-made tracks using audio files from when she was thirteen.
As continuous innovations are made in the field of artificial intelligence, so is the use of this technology in the entertainment industry to recreate datafied versions of people after their death. This begs the question: What are the ethical issues behind the data collection and utilization of individuals after their death?
Deepfakes and AI
One particularly infamous technology used in the entertainment industry, for example, is Deepfakes, a type of neural network called an autoencoder that uses prior data to “reconstruct people” by swapping faces or manipulating facial expressions. It can also “[analyze] the voice records of a person…and [imitate] the voice and the accent, pitch, and pace of a speech” (TRWorld). The utilization of deepfakes continues to rise and “the number of expert-crafted video deepfakes double every six months” (Cybernews).
Ethical and Privacy Concerns
Ethical issues arise when analyzing the utilization of this technology and someone’s data after death. According to the Belmont Report, a list of basic ethical principles and guidelines that address ethical issues, there are concerns for respect of persons and justice. Respect for Persons indicates that the data of humans must be respected and that they should have full autonomy over what can or cannot be collected from them. Therefore, before utilizing someone’s data after death, it is important to request informed consent (possibly prior to their death or to the family of the individual) for the utilization of their data. Meanwhile, justice reminds us to ask who receives the benefits of this and who bears the burden? If someone’s data is taken advantage of for the utilization of someone’s personal benefit and hurting another person or community, this would be a violation. For example, utilizating someone’s face to spread misinformation on the internet after the death (claiming a statement they possibly made in the past). In the case of Carrie Fisher and Selena, is important to ask whether or not they consented to the use of their data after death, giving them respect, and using it fairly.
Furthermore, we can apply the OECD Principles of Corporate Governance to see violations of principles which include but are not limited to use limitation, openness, and accountability. In order to avoid violating these principles, it is important to not take advantage of someone’s data after death and limit their use to only for necessary purposes, be transparent about the collection and use of their data to the public, and be accountable for any mishaps with someone’s data, respectively.
Furthermore, privacy and security concerns and violations can be seen with the utilization of this technology. In one occurrence, a deepfake recorded a video of MIT Prof. Sinan Aral endorsing an investment fund’s stock-trading algorithm without his awareness or consent (Wall Street Journal). Technology like this can harm a person’s identity and reputation as well as spread misinformation. Imagine having your data and information used in this manner even after death? At the moment, the United States has no legal protections over someone’s data after their death. This is also known as post-mortem privacy protection, a federal law that grants the a person the ability to control the dissemination of personal information after their death, which is unavailable due to the limited legal protections with regards to someone’s data.
Moving Forward
Although there are limited legal protections to your data after death, bringing awareness to the ethical issues and privacy concerns is a good start. In addition it’s important to take part in movements towards requesting legal protections for someone’s data rights in the US. One possibility is advocating for government documents to include how you want your data to be used after death (just like consenting to organ donations). Lastly, following practices to protect your privacy such as limiting your digital footprint and understanding companies privacy policies and practices.