Are You Playing Games or Are the Games Playing You?
By Anonymous | October 21, 2022
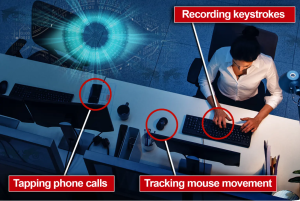
Is our data from playing games being used to manipulate our behavior? When we or our children play online games, there is no doubt we generate an enormous amount of data. This data includes what we would expect from a Google or Facebook (such as location, payment, or device data), but what is not often considered is that this also includes biometric and detailed decision data from playing the game itself. Of course, this in-game data can be used for a variety of purposes such as fixing bugs or improving the game experience for users, but many times it is used to exploit players instead.

Source: https://www.hackread.com/gaming-data-collection-breach-user-privacy/
Data Usage
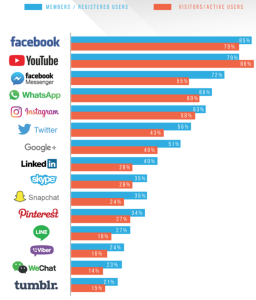
To be more specific, game developers nowadays are utilizing big datasets like those shown in the image above to gain insights into how to keep players playing for longer and spend more money on the game.[1] While big developers have historically had analytics departments in order to figure out how users were playing their game, even smaller developers today have access to middleware created by external parties that can help to refine their monetization strategies.[2] Some gaming companies even aggregate external sources of data on users such as surveys that infer personality characteristics based on how they play the game. In fact, game developers specifically use decision data like dialogue choices to build psychological profiles of their players, allowing the developers to figure out how impulsive or social they are, isolating players that might be more inclined to spend money or be more engaged.[3] Games such as Pokemon GO can take it a step further by aggregating data from our phones such as facial expressions and room noises in order to further refine this profile.
To capitalize on these personality profiles, developers then build in “nudges” into the games that are used to manipulate players into taking certain actions such as purchasing online goods or revealing personal information. This includes on-screen hints about cash shops, locking content behind a pay wall, or forcing players to engage in loot box mechanics in order to remain competitive. This is highly profitable from games ranging from FIFA to Candy Crush, allowing their parent companies to generate billions in revenue per year.[1]

Source: https://www.polygon.com/features/2019/5/9/18522937/video-game-privacy-player-data-collection
Aside from microtransactions, developers can also monetize this data through targeted advertising to their users, matching the best users based on the requirements of the advertiser.[4] Online games not only provide advertisers with the ability to reach a large-scale audience, but to engage players through rewarded ads as well.
Worse Than a Casino for Children
Given external parties ranging from middleware providers to advertisers have access to intimate decision-making data, this brings up a whole host of privacy concerns. If we were to apply Nissenbaum’s Contextual Integrity framework for privacy to gaming, we could compare online games to a casino. In fact, loot boxes specifically function like a slot machine in that it provides uncertain reward and dopamine spikes to players if they win, encouraging addiction. Similar to how a casino targets “whales” that account for the majority of their revenue, online games also try do the same, allowing them to maximize revenue through microtransactions. Yet unlike casinos, online games are not only allowed, but prevalent amongst young adults under the age of 18 and has problems that extend beyond gambling addiction. In Roblox, one of the most popular children’s games in the world (that allows children to monetize in-game items in the games that they create), there have been numerous reports of financial exploitation, sexual harassment, and threats of dismissal for noncompliance.[5]
Conclusion
While there have been efforts to raise awareness about the manipulative practices of online gaming, the industry still has a long way to go before a clear regulatory framework is established. The California Privacy Rights Act is a step in the right direction as it prohibits obtaining consent through “dark patterns” (nudges), but whether gamers will ultimately have the ability to limit sharing of decision data or delete it from the online game itself remains to be seen.
Sources:
[1] https://www.brookings.edu/techstream/a-guide-to-reining-in-data-driven-video-game-design-privacy/
[2] https://www.wired.com/story/video-games-data-privacy-artificial-intelligence/
[3] https://www.polygon.com/features/2019/5/9/18522937/video-game-privacy-player-data-collection
[4] https://www.hackread.com/gaming-data-collection-breach-user-privacy/
[5] https://www.theguardian.com/games/2022/jan/09/the-trouble-with-roblox-the-video-game-empire-built-on-child-labour