Hiding in Plain Sight: A Tutorial on Obfuscation
by Andrew Mamroth | 14 October 2018
In 2010, the Federal Trade Commission pledged to give internet users the power to determine if or when websites were allowed to track their behavior. This was the so called “Do Not Track” list. Now in 2018, this project has been sidelined and widely ignored by content providers and data analytics platforms, with users left to the wolves. So if one wanted to avoid these trackers or at the very least disincentivize their use by rendering them useless, what options do we have?
Imagine the orb weaving spider. This animal creates similar looking copies of itself in it’s web so as to prevent wasps from reliably striking it. It introduces noise to hide the signal. This is the idea behind many of the obfuscation tools used to nullify online trackers today. By hiding your actual request or intentions under a pile of noise making signals, you get the answer you desire while the tracking services are left with a unintelligible mess of information.
Here we’ll cover a few of the most common obfuscation tools used today to add to your digital camouflage so you can start hiding in plain sight. All of these are browser plug-ins and work with most modern browsers (firefox, chrome, etc.)

camo spider
TrackMeNot
TrackMeNot is a lightweight browser extension that helps protect web searchers from surveillance and data-profiling by search engines. It accomplishes this by running randomized search-queries to various online search engines such as Google, Yahoo!, and Bing. By hiding your queries under a deluge of noise, it becomes near impossible or at the very least, impractical to aggregate your search results to build a profile of you.
TrackMeNot was designed in response to the U.S. Department of Justice’s request for Google’s search logs and in response to the surprising discovery by a New York Times reporter that some identities and profiles could be inferred even from anonymized search logs published by AOL Inc (Nissenbaum, 2016, p. 13)
The hope was to protect those under criminal prosecution from government or state entities, from seizing their search histories for use against them. Under the Patriot Act, the government can demand library records via a secret court order and without probable cause that the information is related to a suspected terrorist plot. It can also block the librarian from revealing that request to anyone. Additionally, the term “records” covers not only the books you check out, it also includes search histories and hard drives from library computers. By introducing noise into your search history, this can make snooping in these logs very unreliable.
AdNauseam
AdNauseam is a tool to thwart online advertisers from collecting meaningful information from you. Many content providers make money by the click so by clicking on everything you provide a significant amount of noise without generating a meaningful stamp.
AdNauseam quietly clicks on every blocked ad, registering a visit on ad networks’ databases. As the collected data gathered shows an omnivorous click-stream, user tracking, targeting and surveillance become futile.
FaceCloak
FaceCloak is a tool that allows users to use social media sites such as Facebook while providing fake information to the platform for some users.
Users of social networking sites, such as Facebook or MySpace, need to trust a site to properly deal with their personal information. Unfortunately, this trust is not always justified. FaceCloak is a Firefox extension that replaces your personal information with fake information before sending it to a social networking site. Your actual personal information is encrypted and stored securely somewhere else. Only friends who were explicitly authorized by you have access to this information, and FaceCloak transparently replaces the fake information while your friends are viewing your profile.
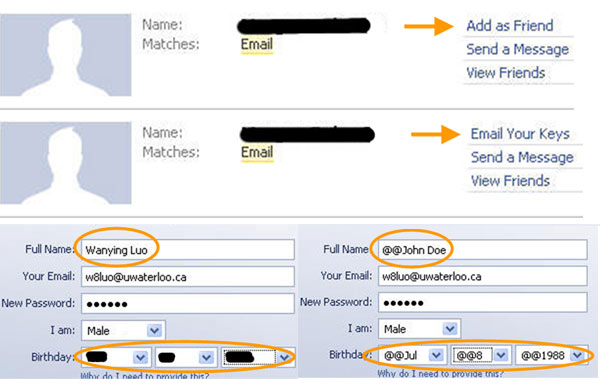
FaceCloak
Conclusion
Online privacy is becoming ever more important and ever more difficult to achieve. It has become increasingly clear that the government is either unable or unwilling to protect it’s citizens privacy in the digital age and more often than not is a major offender in using individuals personal information for dubious goals. Obfuscation tools are becoming ever more prevalent as companies quietly take our privacy with or without consent. Protecting your privacy online isn’t impossible, but it does take work, fortunately the tools exist to take it back.
Reference
Brunton, Finn, and Helen Nissenbaum. Obfuscation: a User’s Guide for Privacy and Protest. MIT Press, 2016.