Overview
Customer experience has become one of the key performance indicator for predicting success or early exit of a fledgling enterprise software company. When shifting the reference point from revenue-driven processes to user experience driven business, the business must rethink how to architect information flow within and outside the company for providing a seamless user experience.
The enterprise software startup considered for this case study was also facing several challenges that was starting to have negative impact on the end user experience. The software processes were ad-hoc, it was difficult to capture customer touch points, drive the open source developer community knowledge base, and was challenging to seamlessly weave the story for customer use cases around the product platform.
The customers experienced a broken software experience across various dimensions like deployment, customer interaction, training, and documentation.
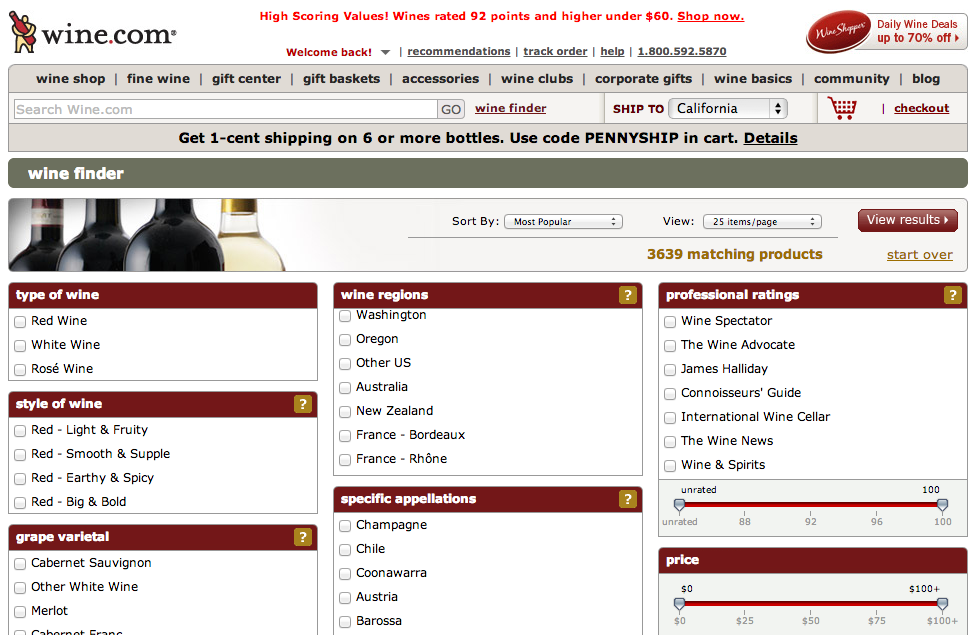
What resources are being used?
As a system designer, it was important to identify information components that had confounded information content. This includes the product documentation, blogs, training material, customer support tickets, and software tickets.The variability in information component implies a large and diverse set of resource descriptions causing categorization challenges for the entire set. In order to classify the diverse set of resources, common properties must be used to identify higher level of abstraction in order to balance precision tradeoff. We organized the resources based on broad categories like posts, product documentation, infographics, and customer tickets. However, even after categorizing the resources based on higher level of abstraction, there was another problem of separating the resources that pointed to the same instance. For example, knowledge base articles and product documentation sometimes referred to the same resource instance. Some resources were composite resources used by cross functional teams like customer support tickets were often used by the product marketing team to extract usecases. This situation caused ambiguity about the number of parts in the resource description decision. It was also important to separate the duality of the tangible embodiment of resources with inherent abstract information resource. For example, the resource distribution channel for example, print, ebook, blog posts, etc. also has the impact on how resources will be organized.
Why are the resources organized?
The teams were facing vocabulary and interoperability issues because of the different document formats being used across various teams. The two teams for example, product documentation and training teams were not able to talk with each other due to absence of single sourcing and common interoperability issues. Additionally, there were several resources for multimedia like videos for training sessions that had separate organization issues. These multimedia resources would have to be classified based on the interactions that are qualitatively different than the other digital resources.
How much are the resources organized?
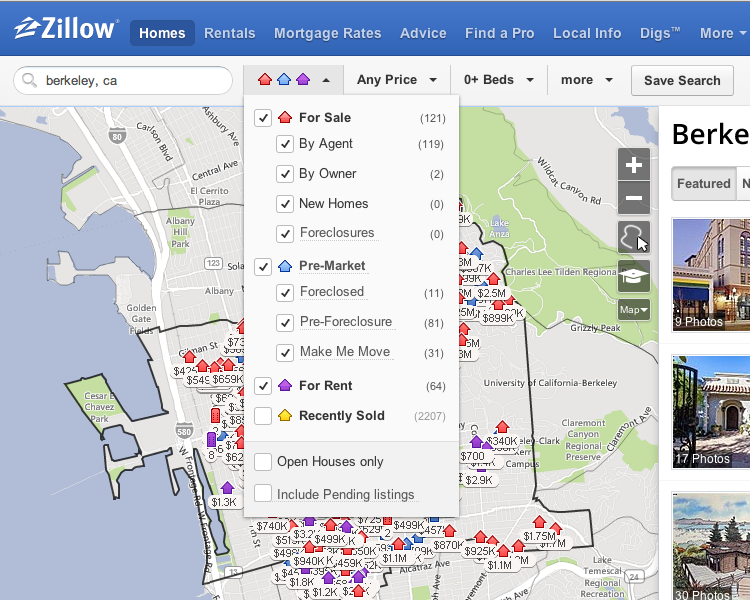
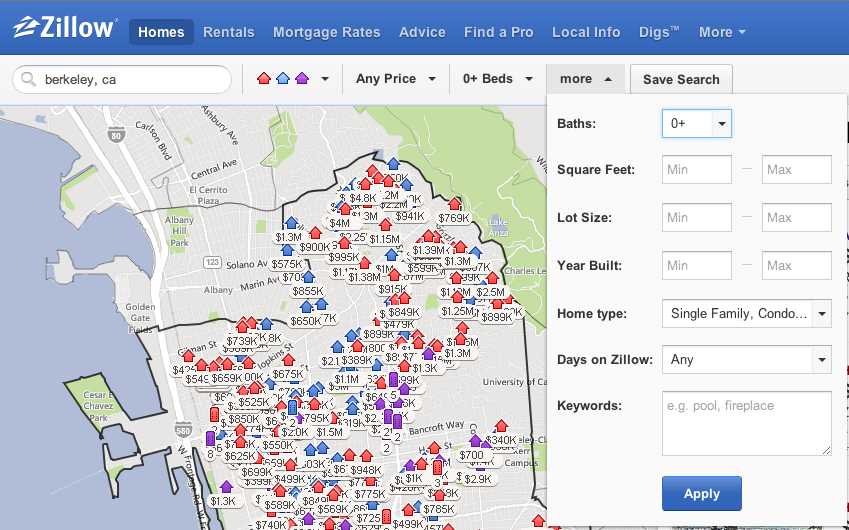
Some resources must be organized based on the intrinsic static properties like category of the resource etc. Other resources must be organized based on the extrinsic dynamic properties like customer salesforce tickets and knowledge base articles must be organized simultaneously. Decisions about the organizations are based on the business goals of providing seamless customer interaction with the product. Because most of the content flow is intertwined in order to provide an end to end product experience it is imperative for the system designer to consider the information flow across different resource components. The XML based resources would follow DocBook standard for organization and interoperability between several platform. An example of these resources would be the documentation and blog posts.
When are the resources organized?
The resources must be organized during creation. Additionally, the resources would also be organized during the maintenance phase in order to maintain the archives based on various versions of the product platform. For the community driven content, (especially the JIRA tickets filed with the open source community) the organization would mostly happen during creation and triage phase.
Who does the organizing?
The contributors, authors, curators, and the automated system are responsible for the content creation and organization. Some of the organization would be done during the creation based on the single sourcing publication solution that would be implemented. Additionally, the end users of the system will also do the organizing by tagging resources like customer tickets and use case based articles.
Other considerations
This was an ambitious project considering the umbrella of components it covered. The most challenging part would be sweeping in the open source content because the company had no control over the form of the content received. Additionally, as the company grows the challenges with content production and localization are also inevitable. Currently, the support center and product documentation teams were able to talk with each other seamlessly, however product marketing and training teams could still not avail of the single source publishing pipeline because of legacy content. Merging these two teams would be another challenging aspect for the system designers.