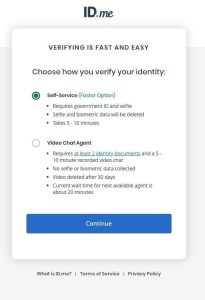
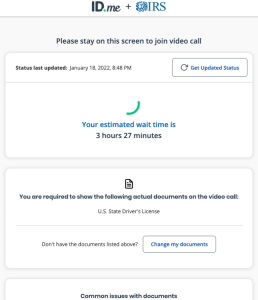
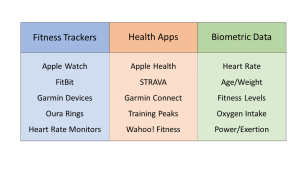
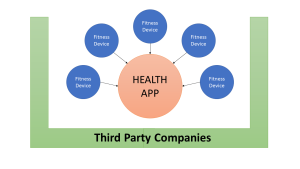
Self-Driving Cars or Surveillance on Wheels?
By MaKenzie Muller | March 2, 2022
Through the years, automotive safety has vastly improved with the help of new technology such as back-up cameras, driver assist functions, automatic lane detection, and self-driving modes. These new features require constant input from their surroundings – including the driver behind the wheel. From dash-cams and 360 degree sensors to infrared scans of driver head movement, our cars may be gathering more data on us than we think.
New and Improved Features

In March of 2020, Tesla announced a software update that would begin the use of it’s driver facing cameras in the Model Y and Model 3 vehicles. These rear-view mirror cameras existed in the cars for almost three years without use. While Elon Musk stated that the cameras were intended to prevent vandalism during Tesla’s taxi program, the release notes asked consumers to allow the camera to capture audio and video in order to “develop safety features and enhancements in the future”. While the software update and enabling the new camera were optional, the tactic of urging drivers to authorize the camera use for research and development casts a shadow on how the information may be used for business purposes.
Keeping passengers safe or putting them at risk?

Driver monitoring systems aren’t limited to just one brand. Trusted makers such as Ford and BMW also deliver driver assist features. In June 2020, Ford announced that it’s newest Mustang and F150 trucks would be equipped with hands-free driving technology on pre-mapped North American highways. To further limit distracted driving, Beverly Bower of JD Power writes, “an infrared driver-facing camera will monitor head positioning and eye movement, even if the driver is wearing sunglasses.” Ford delineates the information they collect about drivers in their vehicles in their Connected Vehicle privacy policy; they gather data about the car’s performance, driving behavior and patterns, audio and visual information, as well as media connections to the car itself. They do not specify how long recordings or other personal information may be stored. The policy specifically recommends that the driver “inform[s] passengers and other drivers of the vehicle that Connected Vehicle Information is being collected and used by us and our service providers.” The company also vaguely states that they retain data for as long as necessary to fulfill their services, essentially allowing them to keep it as long as it is useful for the business. Suggesting that a Ford owner divulge the use of data collection to passengers implores a look into exactly what information is being gathered and why.
Second-hand cars and second-hand data
On the surface, it appears that companies are following privacy guidelines and requirements, but have very little in the way of ensuring that consumers understand the impact of their decisions. Most of the driver assist policies reviewed for this article reiterate the optional use of these features, and that driver data often does not leave the vehicle. The vehicle manufacturers elicit consent from buyers in order to use the services, much in the same manner websites and mobile apps do. The policies also include information about how the data can be retained locally on a SIM card in the console, for example. To that end, owner to owner used car sales introduce a unique potential harm of inadvertently passing personal information onto the next buyer. Ford in particular recommends performing a master reset of the vehicle prior to selling second-hand. Continually, as cars become more and more advanced, it is becoming increasingly difficult to opt out of the many cutting-edge features. Paying premium for the latest models only to not use these pricy features leaves many buyers in a difficult spot.
References
https://www.enisa.europa.eu/news/enisa-news/cybersecurity-challenges-in-the-uptake-of-artificial-intelligence-in-autonomous-driving
https://www.jdpower.com/cars/shopping-guides/what-is-ford-active-drive-assist
Tesla releases new software update with bunch of new features
https://www.optalert.com/optalert-drowsiness-attentiveness-monitoring/
https://news.ucar.edu/132828/favorable-weather-self-driving-vehicles