Physical Implications of Virtual Smart Marketing: How the Rise in Consumerism Powered by AI/ML Fuel Climate Change
By Anonymous | March 16, 2022
Introduction
Suspiciously relevant ads materialize in our social media feeds, our e-mails, and even texts. It’s become commonplace for digital marketing groups to invest in teams of data scientists with the hopes of building the perfect recommendation engine. At a glance, sales are increasing, web traffic is at an all-time high, and feedback surveys imply a highly satisfied customer base. But at what cost? This rise of consumerism, incited by big data analytics, has caused in increase in carbon emissions due to heightened manufacturing and freight. In this blog post, I will explore machine learning techniques used to power personalized advertisements in the consumer goods space, the resulting expedited rise of consumerism, and how our planet, in turn, is adversely affected.
Data Science in the Retail Industry
Data science enables retailers to utilize customer data in a multitude of ways, actively growing sales and improving profit margins. Recommendation engines consume your historical purchase history to predict what you’ll buy next. Swaths of transaction data are used to optimize pricing strategy across all the board. Computer vision is expanding, used to power the augmented reality features in certain mobile apps, such as IKEA’s app that customers can use to virtually place furniture into their very own homes.

But arguably one of the largest use cases would have to be personalized marketing and advertising. Both proprietary and third-party machine learning algorithms have massively improved with time, predicting the unique purchases a single consumer will make with tremendous accuracy. According to a 2015 McKinsey Report, research shows that personalization can deliver five to eight times the ROI on marketing spend and lift sales 10 percent or more [1]. Modern day retailers understand this lucrativeness, and in turn, scramble to assemble expert data science teams. But what of their understanding of the long-term implications beyond turning a profit?
The Rise in Consumerism
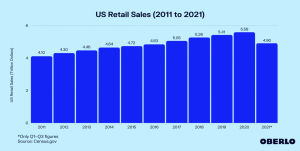
As data science continues to assert its dominance in the consumer goods industry, customers are finding it hard to resist such compelling marketing. This pronounced advancement in marketing algorithms has unabashedly caused a frenzy in purchases by consumers throughout the years. According to Oberlo, the US retail sales number has grown to $5.58 trillion in the year 2020—the highest US retail sales recorded in a calendar year so far. This is a 36 percent increase over nine years, from 2011 [2]. These optimized marketing campaigns, coupled with the advent of nearly instantaneous delivery times (looking at you, Amazon Prime), have fostered a culture that sanctions excessive amounts of consumer spending.
The Greater Rise in Temperature
To keep up with demand, retailers must produce a higher volume of goods. Unfortunately, this increased production will lead to higher pollution rates from both a manufacturing and freight standpoint. These retailers primarily use coal-based energy for their manufacturing, which emits greenhouse gases into the atmosphere. These goods are then transported in bulk by truck, train, ship, or aircraft, exuding carbon dioxide and further exacerbating the problem.
Although consumer goods production is not solely responsible for all emissions, it undeniably contributes to the exponential warming of the planet. According to the National Geographic, NOAA and NASA confirmed that 2010 to 2019 was the hottest decade since record keeping began 140 years ago [3].

Furthermore, these purchased goods will eventually comprise earth’s MSW, or municipal solid waste (various items consumers throw away after they are used). The United States Environmental Protection Agency claims that the total generation of MSW in 2018 was 292.4 million tons, which was approximately 23.7 million tons more than the amount generated in 2017. This is a marked increase from the 208.3 million tons of MSW in 1990 [4]. The decomposition of organic waste in landfills produces a gas which is composed primarily of methane, another greenhouse gas contributing to climate change [5]. There are clearly consequential and negative effects of this learned culture of consumerism.
What You Can Do
To combat climate change, begin by understanding your own carbon footprint. You can perform your own research or you can use one of the many tools available on the internet, such as a carbon footprint calculator (https://www.footprintcalculator.org). If you incorporate less unprocessed foods into your diet, include more locally sourced fruits and vegetables, and avoid eating meat, you are taking small but important steps in the fight against climate change. Consider carpooling or taking public transit to work and/or social events to decrease carbon emissions from your commute. Steps like these seem small, but they build good habits and cultivate lifestyle changes that contribute to the health of our planet.
References
[1] https://www.mckinsey.com/~/media/McKinsey/Business%20Functions/Marketing%20and%20S ales/Our%20Insights/EBook%20Big%20data%20analytics%20and%20the%20future%20of%20m arketing%20sales/Big-Data-eBook.ashx
[2] https://www.oberlo.com/statistics/us-retail-sales
[3] https://www.nationalgeographic.com/science/article/the-decade-we-finally-woke-up-to- climate-change
[4] https://www.epa.gov/facts-and-figures-about-materials-waste-and-recycling/national- overview-facts-and-figures- materials#:~:text=The%20total%20generation%20of%20MSW,208.3%20million%20tons%20in% 201990.
[5] https://www.crcresearch.org/solutions- agenda/waste#:~:text=The%20decomposition%20of%20organic%20waste,potential%20impact %20to%20climate%20change.