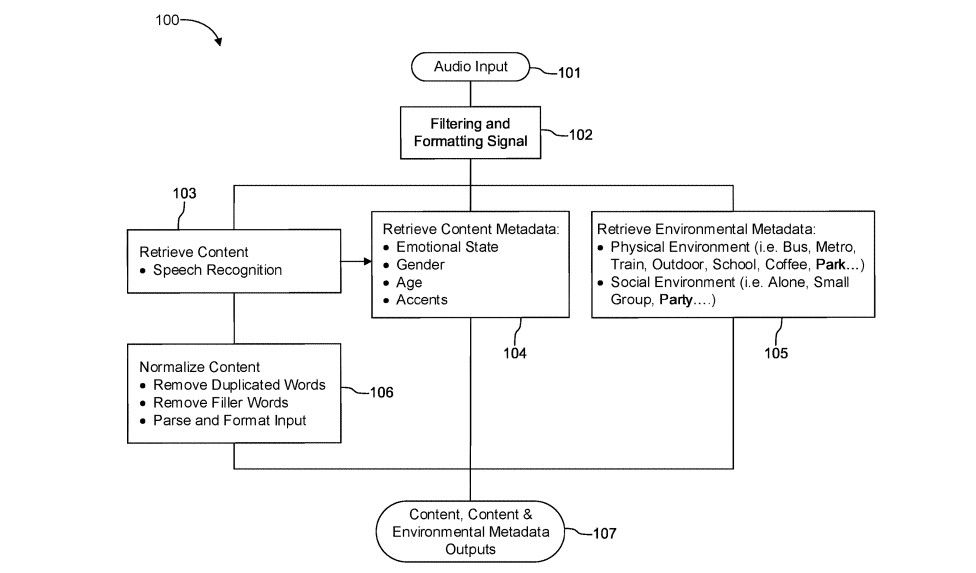
Privacy Policies: Manufactured Consent
Angel Ortiz | July 7, 2022

The conversation surrounding privacy policies and terms of service (ToS) has grown in public interest these recent years, and with it concern on what exactly people are agreeing to when they “click” accept. This more noticeable interest in the agreed upon terms for the use of one’s private information (as well as its protection) was likely sparked in part by the Facebook/Britannica Analytica breach of privacy scandal of 2018 (Confessore, N. 2018). This event stirred a social discussion on how companies protect our data and what they are allowed to do with the data we provide. However, despite this burgeoning unease for the misuse of user intelligence, it is all too common to find ourselves blindly accepting the ToS of some website or application, all because we find it too much of a nuisance to read. While it may be true that much of this behavior is the responsibility of the consumer, one must also wonder what obligations companies have when making their policies. After all, if it is a frequent phenomenon that users accept a ToS solely due to its inconvenience, then one must begin to wonder whether this bothersome nature is purposely infused into the text for this very reason.
Complexity of Privacy Policies

In May 2014, the California Department of Justice outlined several concepts privacy policies should comply with in order to properly disseminate their contents to users. One of these key principles was “Readability”, in which they specified that privacy policies should (among other things) use short sentences, avoid the use of technical jargon, and be straightforward (State of California Department of Justice & Harris, K., 2014). Similarly, the FTC also advocated for more brief and transparent privacy policies in a report they published in 2012 (Federal Trade Commission, 2012, p. 60-61). Despite these guidelines, privacy policies seem more complex than ever before, and this complexity does not necessarily stem from the length of the text.
While there are some excessively long privacy policies, researchers from Carnegie Mellon University estimated that (on average) it would take 10 minutes to read a privacy policy if one possessed a secondary education (Pinsent Masons, 2008). While this is somewhat of a long read for some services, most would argue that they could easily dedicate 10 minutes of their time to read a privacy policy for a service of more importance. However, the problem with these policies is usually in the complexity of the reading rather than its length. In 2019, The New York Times published an article where they used the Lexile test to determine the complexity of 150 privacy policies from some of the most popular websites and applications. They found that most of the policies required a reading comprehension exceeding the college level to understand (Litman Navarro, K. 2019); for reference, it is estimated that only 37.9% of Americans, who are 25 or older, have a bachelor’s degree (Schaeffer, K. 2022). At face value, this would mean that a non insignificant portion of the U.S. population does not have the education to understand what some of these privacy policies entail.
Purposeful Inconvenience?
Some may conjecture that this complexity is purposefully manufactured with the objective of inconveniencing consumers into not reading privacy policies before accepting a ToS. While this is an enticing thought, we cannot disregard that there is a less nefarious explanation for why privacy policies are written in such a complex manner: legal scrutiny. It is the opinion of some experts such as Jen King, the director of consumer privacy at the Center for Internet and Society, that privacy policies exist to appease lawyers (Litman-Navarro, K. 2019). That is to say, privacy policies are not written with consumers as the audience in mind.
Solution
Regardless of what the real intent behind the complexity of privacy policies is, it is undeniable that its effect is the inability of some users to properly comprehend them or, at least, dedicate the time to do so. Therefore, we must ask, how can we solve this problem? Often the simplest solution is the correct one, and this holds true here as well. If the problem stems from privacy policies not being written for consumers, then companies should begin writing their policies with consumers in mind. This would necessarily entail making the texts shorter, more to the point and reduced in the use of “legalese”.
Conclusion
It is important for individuals to take the time to properly understand what they are agreeing to when they accept a ToS, and their corresponding privacy policies. This, of course, is not likely the norm and most would place the fault of this behavior on the consumers. However, when some of these policies are made so long and complex that it is not only an inconvenience but an impossibility for many users to properly comprehend what they are agreeing to, then I would argue that this common practice is not the fault of the consumer but of the policy makers themselves. We no longer live in a time where we have the luxury of not partaking of services that intake our data; as such, it is my hope that as this discussion continues to grow, more policy writers shift focus to include user understanding in their privacy policies. Otherwise, I suggest we make Law School cheaper so that more people can obtain degrees in privacy policy comprehension.
References
Average privacy policy takes 10 minutes to read, research finds. (2008, October 06). Pinsent Masons. Retrieved July 3, 2022, from https://www.pinsentmasons.com/out law/news/average-privacy-policy-takes-10-minutes-to-read-research-finds#:%7E:text=The%20average%20length%20of%20privacy,take%2010%20minutes% 20to%20read.
Confessore, N. (2018, November 15). Cambridge Analytica and Facebook: The Scandal and the Fallout So Far. The New York Times. Retrieved July 3, 2022, from https://www.nytimes.com/2018/04/04/us/politics/cambridge-analytica-scandal-fallout.html
Federal Trade Commission. (2012, March). PROTECTING CONSUMER PRIVACY IN AN ERA OF RAPID CHANGE. https://www.ftc.gov/sites/default/files/documents/reports/federal trade-commission-report-protecting-consumer-privacy-era-rapid-change recommendations/120326privacyreport.pdf
Litman-Navarro, K. (2019, June 13). Opinion | We Read 150 Privacy Policies. They Were an Incomprehensible Disaster. The New York Times. Retrieved July 3, 2022, from https://www.nytimes.com/interactive/2019/06/12/opinion/facebook-google-privacy-policies.html
Schaeffer, K. (2022, April 12). 10 facts about today’s college graduates. Pew Research Center. Retrieved July 3, 2022, from https://www.pewresearch.org/fact-tank/2022/04/12/10- facts-about-todays-college graduates/#:%7E:text=As%20of%202021%2C%2037.9%25%20of,points%20from%203 0.4%25%20in%202011.
State of California Department of Justice, & Harris, K. (2014, May). Making your Privacy Practices Public. Privacy Unit. https://oag.ca.gov/sites/all/files/agweb/pdfs/cybersecurity/making_your_privacy_practices_publi c.pdf?