
Privacy Computing
By Anonymous | October 29, 2021
The collection, use, and sharing of user data can enable companies to better judge users’ needs and provide better services to customers. From the perspective of contextual integrity [1], all the above are reasonable. However, studying the multi-dimensional privacy model [2] and privacy classification method [3], there are many privacy risks in the processing and sharing of user data, such as data abuse, third-party leakage, data blackmail, and so on. Due to the protection of the value of data and the protection of user privacy authorization by enterprises and institutions, data is stored in different places, and it is difficult to effectively connect and interact with each other. Traditional commercial agreements cannot effectively protect the security of data. Once the original data is out of the database, it will face the risk of completely losing control. A typical negative case is the Cambridge Gate incident on Facebook. The two parties follow the agreement: Facebook will transfer tens of millions of user data to Cambridge Analytica for academic research [4]. However, once the original data was released, it was completely out of control and used for non-academic purposes, resulting in huge fines facing Facebook. It is needed to provide a more secure solution from the technical level to ensure that the data usage rights are subdivided in the process of data circulation and collaboration.
“Privacy computing” is a new computing theory and method for protecting the entire life cycle of private information [5]. Privacy leakage, privacy protection and privacy calculation models along with the separation of the right to use the axiom system and other methods, are used to protect the information while using it. Privacy computing is essentially to solve data service problems such as data circulation and data application on the premise of protecting data privacy. The concept of privacy computing includes: “data is available but not visible, data does not move the model moves”, “data is available but invisible, data is controllable and measurable”, “not sharing data, but sharing the value of data” and so on. According to the main related technologies of privacy computing technology in the market, it can be divided into three categories: multi-party secure computing, trusted hardware, and federated learning.
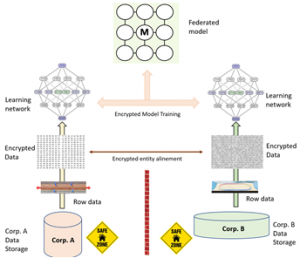
Federated learning is a distributed machine learning technology and system that includes two or more participants. It allows people to perform specific algebraic operations on plaintext data to get the result that is encrypted, and the result obtained by decrypting it is the same as the result of performing the same operation on the plaintext. These participants conduct joint machine learning through a secure algorithm protocol and can jointly model and provide model reasoning and prediction services in the form of intermediate data exchange. And the model effect obtained in this way is almost the same as the effect of the traditional central machine learning model, as shown in Fig.1.
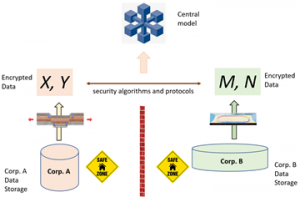
Secure multi-party computation is a technology and system that can safely calculate agreed functions without requiring participants to share their own data and without a trusted third party. Through security algorithms and protocols, participants encrypt or convert data in plain text before providing the data to other parties. No participant can access other parties’ data in plain text, thus ensuring the security of all parties’ data, as shown in Fig.2.
Trusted computing includes a security root of trust that is first created, and then a chain of trust from the hardware platform, operating system to the application system is established. On this chain of trust, the first level of certification is measured from the root, and the first level of trust is the first level. This realizes the step-by-step expansion of trust, thereby constructing a safe and trustworthy computing environment. A trusted computing system consists of a root of trust, a trusted hardware platform, a trusted operating system, and a trusted application. Its goal is to improve the security of the computing platform.
With the increasing attention in various fields, privacy computing has become a hot emerging technology and a hot track for business and capital competition. Data circulation is a key link to release the value of data, and privacy computing technology provides a solution for data circulation. The development of privacy computing has certain advantages and a broad application space. However, due to the imperfect technology development, it also faces some problems. Whether it is innovation breakthroughs realized by engineering or optimization and adaptation between software and hardware, the performance improvement of privacy computing has a long way to go.
References:
【1】 Helen Nissenbaum, “Privacy as Contextual Integrity”, Washington Law Review, Volume 79, Number 1 Symposium: Technology, Values, and the Justice System, Feb 1, 2004.
【2】 Daniel J. Solove, “A Taxonomy of Privacy”, The University of Pennsylvania Law Review, Vol. 154, No. 3, pp. 477-564, 2006. https://doi.org/10.2307/40041279.
【3】 Mulligan Deirdre K., Koopman Colin and Doty Nick 2016, “Privacy is an essentially contested concept: a multi-dimensional analytic for mapping privacy”, Phil. Trans. R. Soc. A.3742016011820160118 http://doi.org/10.1098/rsta.2016.0118
【4】 Confessore, Nicholas (April 4, 2018). “Cambridge Analytica and Facebook: The Scandal and the Fallout So Far”. The New York Times. ISSN 0362-4331. Retrieved May 8, 2020.
【5】 F. Li, H. Li, B. Niu, J. Chen,” Privacy Computing: Concept, Computing Framework, and Future Development Trends”, journal of engineering 5, 1179-1192, 2019.