You Wish You Were Being Recorded
By Joseph Wood | May 28, 2021
Full Disclaimer: I work for Siri
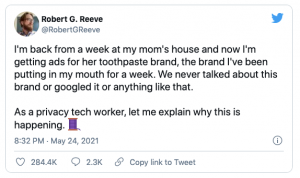
Have you ever been talking about a product with a friend and immediately received an ad for it? Microphones are everywhere especially in the devices you interact with the most from phones, and computers to remotes and cars. These microphones are sold to consumers as accessibility tools that make device actions intuitive and easy to use. If you’ve ever thought the microphones were recording more than just the actions requested of them, you wouldn’t be alone. About 43% percent of Americans believe these devices record conversations without their permission (Fowler, 2019). How else are the highly targeted ads explained? Sadly, there is no credible evidence suggesting that these devices are constantly recording you. It’s much worse.
Audio is incredibly expensive to process from a computing and storage standpoint. It needs to be transcribed and even the best transcription services in the world struggle to do this effectively in perfect environments, let alone in real world homes. The amount of dialogue that would need to be collected, stored, correctly transcribed, and processed to get to a point where it might be able to suggest something useful to buy is a huge hurdle. Not to mention the monetary fines these companies would face if their operation were ever revealed. But luckily for them, they don’t need to risk anything because you’ve already agreed to an easier option.
There’s an endless amount of data that is cheaply and readily available for these companies. That’s your digital footprint. Every time you land on a website, look at a new shirt, or spend a second on your favorite mind numbing app, this information is collected, stored, and shared. Companies like Facebook and Google can put together the crumbs you leave across the internet to construct exactly the types of interests you have regardless of whether you did so on their platforms. Facebook has a number of partner marketing firms that it shares data with and even has a tool called Facebook Pixel. Facebook Pixel is embedded into third party websites to track any number of user actions, how long they spend looking at certain components, and if users are revisiting pages. Facebook can even track users’ web browsing habits when users surf on the same browser they’re logged into Facebook on. But logging out is not enough. Facebook can still identify users from IP addresses, or when they use the “sign in with Facebook” option on a different website, or through comparing the email and phone number users share across the internet.
A common practice these ads take is steering consumers back to products they were interested in but eventually passed on. Competitors can also choose to place ads at these times. If the algorithms noticed consumers shopping for items at Target for example, Facebook could give Walmart the option to place ads to steer consumers to their site. Because Facebook knows so much about its users, it can even tell when users of a certain type are buying a specific product, and decide whether to show it to other similar users. The company doesn’t just collect data from other websites, it can use these same websites to continue pummeling users with targeted ads. Even Facebook’s own tools that were developed to combat the negative press it receives are mainly just to remove the way in which it uses data to suggest ads. It does not stop the collection process. All of this allowed by a ridiculous Terms and Conditions notification you likely clicked through. And this is just one company.
Recently, more companies have tried to limit the sharing of users’ data. In 2020, Apple announced that it would give iOS users more control over data sharing and ultimately the ability to cut off any sharing within the apps they use. This was expected to be a huge blow to ad companies, but both Google and Facebook stock prices are sitting at all time highs. This hints at exactly how ingrained these companies have become in all the experiences consumers use that the largest technology company in the world potentially cutting them off had no long term effect on their business outlook.
So the next time you see such a highly targeted ad, think about where the data is actually coming from.