
Machine Learning bias in Word Embedding Algorithms
By Anonymous | May 28, 2021
I have studied a Natural language processing course at UC Berkeley for the last few months. One of the key points in NLP is word embedding. For those who are not familiar with NLP, here is a simple explanation about word embedding: It is a learned representation for text where words that have the same meaning have a similar representation.Word embedding methods learn a real-valued vector representation for a predefined fixed-sized vocabulary from a corpus of text.The learning process is either joint with the neural network model on some task, such as document classification, or is an unsupervised process, using document statistics.
In word embedding models, each word in a given language is assigned to a high-dimensional vector, such that the geometry of the vectors captures relations between the words. For example, the cosine similarity between the vector representation of the word King will be closer to the word Queen than to television, because King and Queen are similar meaning words but television is quite different. To preserve the semantics of the natural language in its entirety, word embeddings are usually trained on huge databases, for example, Google News (about 100 billion words). And the huge database brings us the algorithm gender bias.
In our word embedding algorithm, we have:
Man + royal = King
Woman + royal = Queen
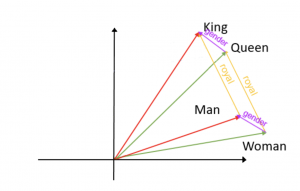
and that looks great. That’s how we want our algorithm to learn our language. But when comes to some occupation, the algorithm could be biased. One example would be:
Man + medical occupation = Doctor
Woman + medical occupation = Nurse
From this example, we could see ‘stereotype’ with our algorithm. If the man is corresponding to the doctor, the woman should be corresponding to the doctor as well. However, the algorithm doesn’t think in that way.
And here is a more biased example with our word embedding algorithm:
If we have Man corresponding to programer and try to find what woman corresponding to, the algorithm would bring us, homemaker. The result is unbelievable and we need to think about why this is happening. The word programmer and homemaker are neutral to gender by its definition, but the word embedding model trained on the google news corpus finds that programmer is closer with male than female because of the social perception we have of this job, and that is how people use English. Therefore, we can don’t simply blame the word embedding algorithm as biased. We should think about ourselves, are we think or speak in a biased way and the algorithm catches those biased points and generate the biased model.
Dive more deeply into gender bias in word embedding, here are a two-word cloud showing the K-nearest embedding neighbors of man and women.

In the man’s subgroup, we find businessman, orthopedic_surgeon, magician, mechanic, etc, and In the woman’s group, we find housewife, registered_nurse, midwife, etc. As we can see from the result, the word embedding algorithm is catching people’s stereotypes about the occupation in the google news dataset.
A more shocking result is the leadership words people use to describe people.

There are over 160 leadership words that use to describe a man but only 31 leadership words use to describe a woman. The number of words already speaks a lot. If you are interest, you can use this website to generate more word cloud (http://wordbias.umiacs.umd.edu/)
Until now, a lot of people are still fighting for gender equality. The word embedding algorithm is ‘biased’. But to me, the real question is: Is the algorithm biased or the language, from which the algorithm learned, is biased. That’s the confounding problem that we need to think about and work on.
References
Gender Bias, Umiacs.umd, wordbias.umiacs.umd.edu/.
Buonocore, Tommaso. “Man Is to Doctor as Woman Is to Nurse: the Dangerous Bias of Word Embeddings.” Medium, Towards Data Science, 3 Mar. 2020, towardsdatascience.com/gender-bias-word-embeddings-76d9806a0e17