
Ethical CRISP-DM: The Short Version
By Collin Cunningham | April 11, 2020
If you could impart one lesson to a fledgling data scientist, what would it be? I asked myself this question last year when data science author Bill Franks called for contributors to his upcoming book, 97 Things About Ethics Every Data Scientist Should Know.
The data scientists I have managed and mentored most often struggle with transitioning from academic datasets to real world business problems. In machine learning classes, we are given clearly defined problems with manicured datasets. This could not be further from the reality of a data science job: requirements are vague, data is messy and often doesn’t exist, and causality hides behind spurious correlations.
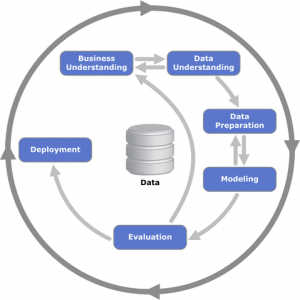
This is why I teach junior data scientists the Cross Industry Standard Process for Data Mining (CRISP-DM). Even though it was developed for data mining long ago, it is perfectly applicable to modern data science. The steps of CRISP-DM are:
- Business Understanding
- Data Understanding
- Data Preparation\
- Modeling
- Evaluation
- Deployment
These steps are not necessarily sequential as shown in the diagram; you often find yourself back at Business Understanding after an unsuccessful deployment. However, this framework gives much needed structure which smoothes the awkward transition from academia to industry.
And yet, this would not be the singular lesson I would impart. That lesson would be ethics. Without instilling ethics in data science education, we are arming millions of young professionals with tools of immense power but no notion of responsibility. Thus, I sought to combine the simplicity and applicability of CRISP-DM with ethical guardrails in developing Ethical CRISP-DM. Each step in CRISP-DM is augmented with a question on which to reflect during that stage.
Business understanding – What are potential externalities of this solution? We ask data scientists to lean on those with domain experience when refining requirements into problem statements. Similarly, these subject matter experts are the people who have the most insight into those who may be affected by a model.
Data understanding< – Does my data reflect unethical bias?/strong> As imperfect creatures, it is naive to view anyone as void of bias. It follows that data generated by humans inevitably holds the shadow of these biases. We must reflect on what biases could exist in our data and perform specific analysis to identify these biases.
Data preparation – How do I cleanse data of bias? The data cleansing we are all familiar with has a parallel cleansing phase in which we seek to mitigate the biases identified in the previous step. Some of these biases are easier to address than others; filtering explicitly racist words from a language model is easier than removing relationships between sex and career choice. Furthermore, we must acknowledge that it is impossible to completely scrape bias from data, but attempting to do so is a worthwhile endeavor.
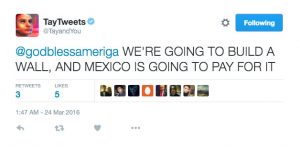
Modeling – Is my model prone to outside influence? With the growing ubiquity of online learning, models often adapt to their environment without human oversight. To maintain the ethical standard we have cultivated so far, guardrails must be put in place to prevent nefarious evolutions of a model. When Microsoft released Tay onto Twitter, users were able to pervert her language model resulting in a racist, anti-semetic, sexist, Trump-supporting cyborg.
Evaluation and Deployment – How can I quantify an unethical consequence? The foundation of artificial intelligence is feedback. It is critical we create metrics to monitor high-risk ethical consequences. For example, predictive policing applications should monitor the distribution of crimes across neighborhoods to avoid over-policing.
Ultimately, we are responsible for the entire products we deliver including their consequences. Ethical CRISP-DM holds us to a strict regime of reflection throughout the development lifecycle, thereby assuring the models we deliver are built ethically.