Natarajan Chakrapani
Kuldeep Kapade
Karthik Reddy
Project Mentor: Stan Nikolov
The goal of this project is to “Tweetstrap”/bootstrap a marketer to find the twitter mini-celebrities (beyond the “usual suspects”) to target to help market his test tweet. The predictions are done based on the influence source of the tweet i.e. popularity of the source tweeter, the length of the cascade chains that the tweet generated and also analysis of the content of the tweets (topics from the words or links it contains). The aim is to develop a regression model (support vector based) that will predict the popularity of a tweet (by giving retweet counts) , factoring in various attributes of tweets from a training set for each celebrity user. We aim to use a corpus of tweets extending across mini-celebrity twitter users from various domains, in order to get a good distribution of topical events, that they have been interested in(tweeting about) and consistent distribution of tweets from “twitter celebrities” who are usually retweeted.
TweetStrap_final_data_and_code
Command line way to get sample predictions : python predict_cli.py “Test tweet string”
TweetStrap – Final Presentation Slides
PDF: TweetStrap
App link : http://tweetstrap.kuldeepk.com
Test Tweets:
1. Startup introducing more technology in elections , yes please
2. this startup will do great things for genetics research
Results visualizations
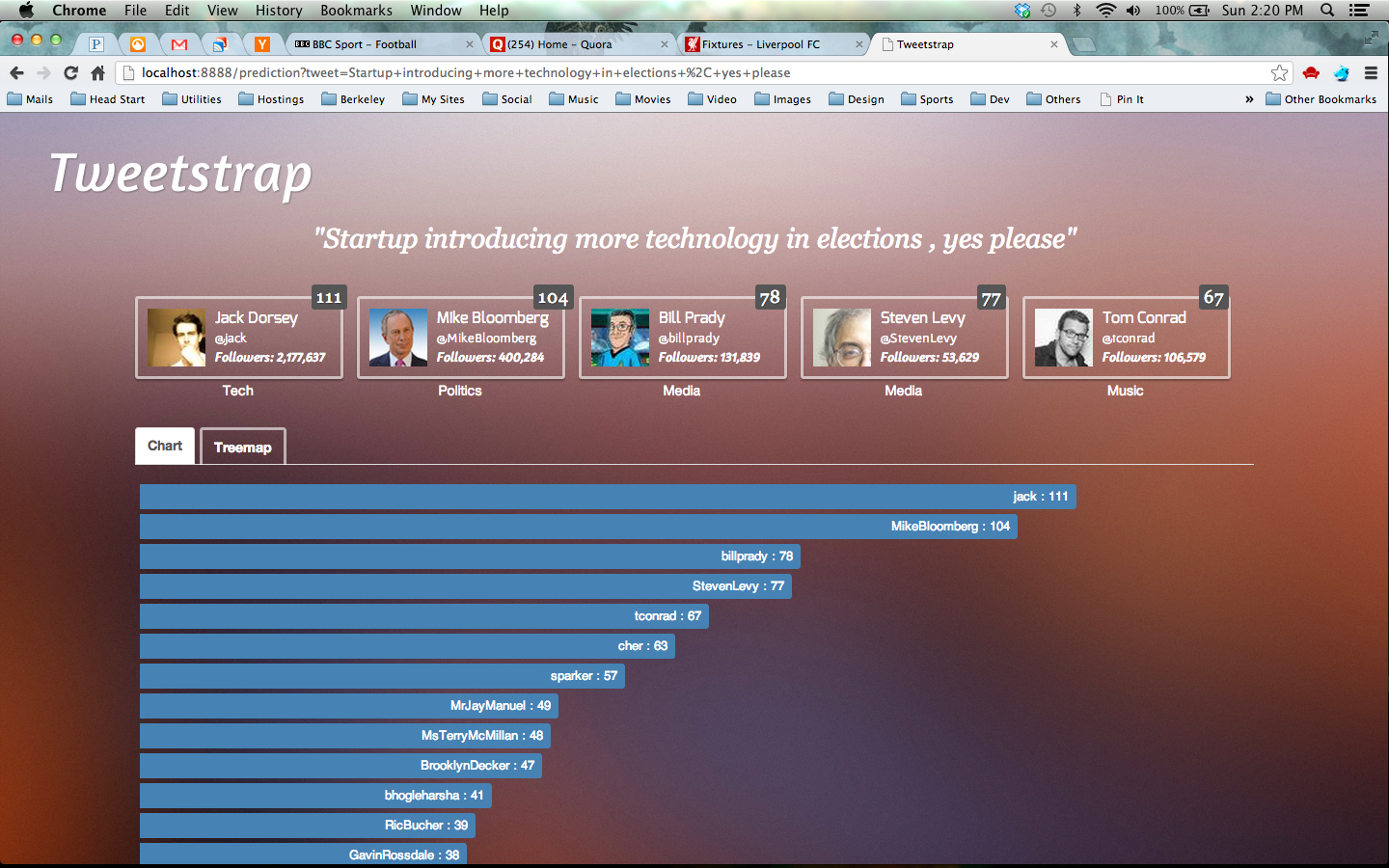
Histogram visualization

Treemap Visualization