TEAM #2 City/Mayor
CONTEXT: This is an internal, actionable report on the effectiveness of police stops for the Los Angeles Mayor. Our analysis looks at the police stop accuracy rate, i.e., the percentage of stops that are immediately followed with post-stop activity (as opposed to unnecessary stops which do not justify further activity). We showcase the 5 most effective and 5 least effective neighborhoods, and then further breakdown the police stop effectiveness by race for each neighborhood.
ACTIONABILITY: This data could be used to identify the top performing police precincts, reward their success, and analyze what specifically is superior in their policies and practices. Ultimately, the goal would be to transfer those policies, practices and perhaps even personnel to the lowest performing precincts.
What is your story?
Working in the mayor’s office, we have decided to create an internal, actionable report for the Mayor that cuts to the essentials of what can be quickly acted upon due to the Mayor’s limited time. We focus on the ratio of “Stops with Post-Stop Activity” / “Total Frisk Stops” in ten different neighborhoods across the city to convey the efficacy of Stop-and-Frisk legislation. We focus on the top five and bottom five precincts in order to best understand which practices lead to their success or failure. Additionally, we break down the police stop efficacy by race for each neighborhood to explore the possibilities of racial discrimination in the law’s application.
How does the selected data support your story?
The data allows us to ask, “Do some people get stopped and frisked for no reason?” The answer is yes, the residents of North Hollywood, West Valley, West LA, Devonshire and Pacific are over twice as likely to be stopped for no reason as the more effective neighborhoods like Foothill, Seventy-Seven, Central Bureau, Mission and Newton.
The data allows us to ask further, “Is there racial bias in who is stopped for no reason?” Given the national statistics in white versus black treatment by the police, one might assume that blacks are more likely to be stopped for no reason, but surprisingly, this “police stop efficacy” measurement is roughly equivalent between whites and blacks in all the neighborhoods. In other words, when blacks and whites get stopped and frisked in Los Angeles, they have a similar likelihood of experiencing further police activity, which suggests that blacks are not suffering discrimination. One surprising statistic is that Asians are the most likely to be stopped and frisked for no reason; in every single neighborhood, the “police stop effectiveness” is the lowest for Asians than for any other race.
Despite these interesting trends, our data is missing several key metrics: are more blacks getting stopped overall? We do not look at absolute numbers. Are fewer Asians stopped on average? We do not take into account the population balance of the different races in each neighborhood. It is possible that blacks underrepresented in the overall population but overrepresented in the percentage of stop-and-frisk incidents. Also, if blacks have an equal or even slightly higher percentage of post stop activity, is that really because police “accuracy” is higher, or could it be because whites get let off the hook slightly more often? Our chosen metric of “stop accuracy” uncovers surprising insights, but begs further investigation.
What data did you omit and why?
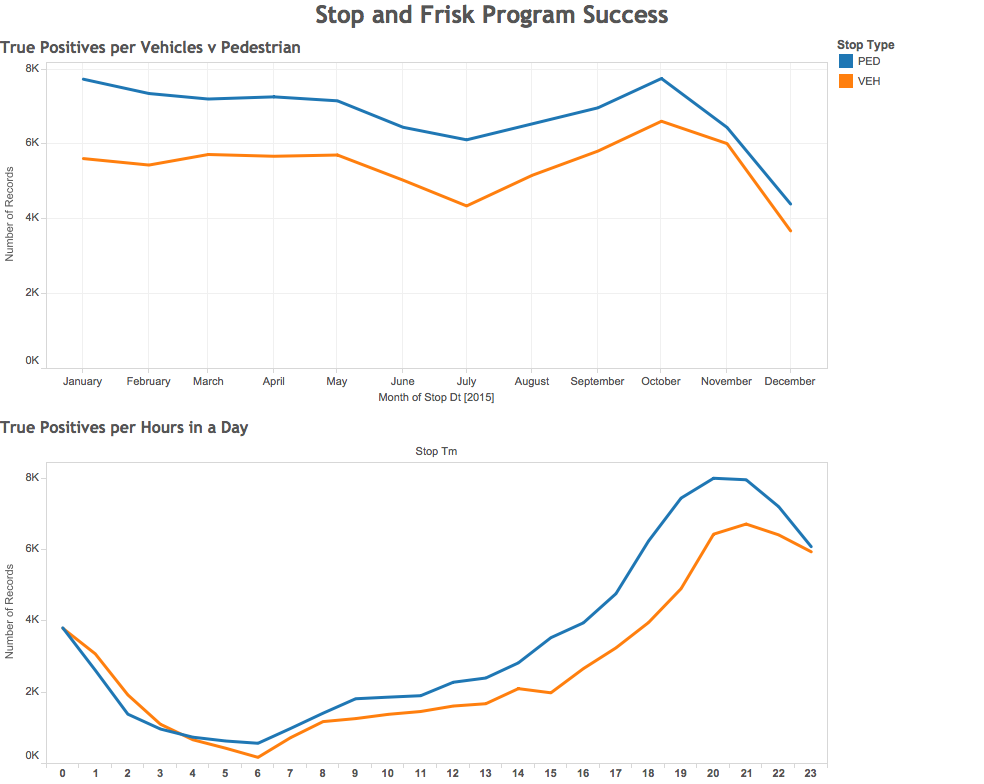
The most significant omission was the data (race and ID number) about the particular officers that were carrying out this law. Though these could be important for discovering the “accuracy” (in terms of the aforementioned ratio) of various officers as well as their personal, racial biases, its is both out of the scope of our report and outside the purview of the mayor to scrutinize individual officers in a city whose police force numbers over 10,000. Following the same logic of including only the information that could be absorbed in a limited window of time, other variables such as time of day, date of stop, and stop type (vehicle or pedestrian) were omitted.
How does the representation support your story?
The representation supports our story because bar graphs are simple to interpret, and keeping the y-axis the same for all graphs makes it easy to make comparisons between different towns and different races. For example, bar graphs made it easy to see that blacks and whites have about the same “stop accuracy” with it being slightly higher for blacks. Simplifying the color of the background and bar graphs makes it instantly recognizable which towns have more effective police stop policies (blue) versus those that do not (orange).
What visual metaphor(s) did you use and why?
The bar graph was chosen because it was the most immediately comprehensible. Though we considered using a map with pie charts and various layers with more sophisticated graphics, owing to the limited amount of time provided by our scenario of meeting with the mayor, we agreed that bar graphs would be the most efficient means of communicating the necessary information. The more effective neighborhoods are coded blue to signify well-being and stability, whereas the least effective neighborhoods are coded orange to signify danger and instability.