Your Social Credit Score: Everything and Everywhere Recorded and Analyzed
By Anonymous | October 20, 2022
Imagine a world where your hygiene, fashion, and mannerisms directly affect your ability to rent an apartment. Every part of you is nitpicked for the world and reflected back to your social credit score which in turn affects your career, finances, and even living situation. Seems extreme, right? Well, this scenario is becoming a reality to Chinese citizens with the country’s Social Credit System.

[IMAGE1: scored_passerbys.jpg]
What is it?
Though China has had ideas about a credit system since 1999, the official Chinese Social Credit System was announced in 2014 after building the necessary infrastructure for the system to be added upon. By using a combination of data gathering and sharing, curation of blacklists and redlists, and punishments, sanctions and rewards, the system would uphold values like financial creditworthiness, judicial enforcement, societal trustworthiness, and government integrity. With the right score, you can expect rewards like getting fast-tracked for approvals or having fewer inspections and audits. But if you have the wrong score, you can face punishments like employment, school, and even travel bans. From this, we can see the system as an oppressive way to force “good behavior” despite the methods being invasive and dismissive of their people’s privacy and autonomy.
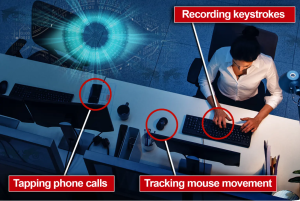
The main cause of concern though is the integration of technology into this “social credit system”, namely with the use of their 200 million surveillance cameras from their Artificial Intelligence facial recognition project aka SkyNet, online behavior tracking systems in all spots of the internet, and predictive analytics for identifying “political violations”. With all these technologies at their disposable, we can see the numerous different privacy harms being committed without any direct consent from their citizens.

[IMAGE2: commuters_and_cameras.jpg]
What are the privacy harms?
This entire system has many potential data risks from data collection to the data analysis to the actions after the predictive analysis. On top of that, I want to reiterate that the citizens had never given consent to participate in such an invasive system.
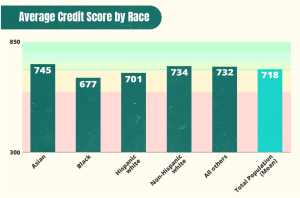
How is it ethical to gather so much sensitive data in a single system and allow numerous data scientists to have access to such personal data? Even if the participants are anonymous, it doesn’t change the fact that these scientists have access to personal identifying data, financial data, social media data, and more; a unique ID would do nothing to protect these participants from bad actors hoping to use this data in a malicious way. Additionally, the government is tight-lipped about how all this data computes a score that affects the participant’s own livelihood and potentially their dependents. This single score dictates so much, yet there isn’t a way for citizens to gain insight into the system or have some technological due process to let the government know if there is an issue. This clear lack of transparency from the system’s creators makes the treatment oppressive to everyone involved.
In addition to the lack of transparency, there is a clear lack of accountability and again due process that would allow some form of correction if the algorithm doesn’t correctly output a score reflective of a citizen’s standing. Like with all data-related endeavors, there is an inherent bias that comes with how the data is being analyzed and what comes out of it; if someone who doesn’t know much about the day-to-day struggles of a Chinese citizen, how can they correctly infer from the data the relative standing of said citizen? How can a couple of algorithms accurately score more than a billion citizens in China? There are bound to be numerous experiences and actions that may actually be okay in the eyes of a human being but deemed “dishonorable” in the logic of the algorithms. By not having an explanation of the system or even a safeguard to avoid situations like this, there are bound to be numerous participants that needlessly fight against a system built against them from the very beginning.
What can we learn from this?
Just like with any system built on people and their data, there is a level of harm committed against the participants that we need to be aware of. It’s important to continue advocating for the rights of the participants rather than the “justice” of the project because incorrect or rushed uses of the data can create harmful consequences for those involved. From this analysis of China’s Social Credit System, we hopefully can learn a thing or two about how powerful the impact of data can be in the wrong context.
Sources
Donnelly, Drew. (2022). “China Social Credit System Explained – What is it & How Does it Work?”. https://nhglobalpartners.com/china-social-credit-system-explained/
Thoughts, Frank. (2022). “Social Credit Score: A Dangerous System”. https://frankspeech.com/article/social-credit-score-dangerous-system
Reilly, J., Lyu, M., & Robertson, M. (2021). “China’s Social Credit System: Speculation vs. Reality”. https://thediplomat.com/2021/03/chinas-social-credit-system-speculation-vs-reality/